Hi dears,
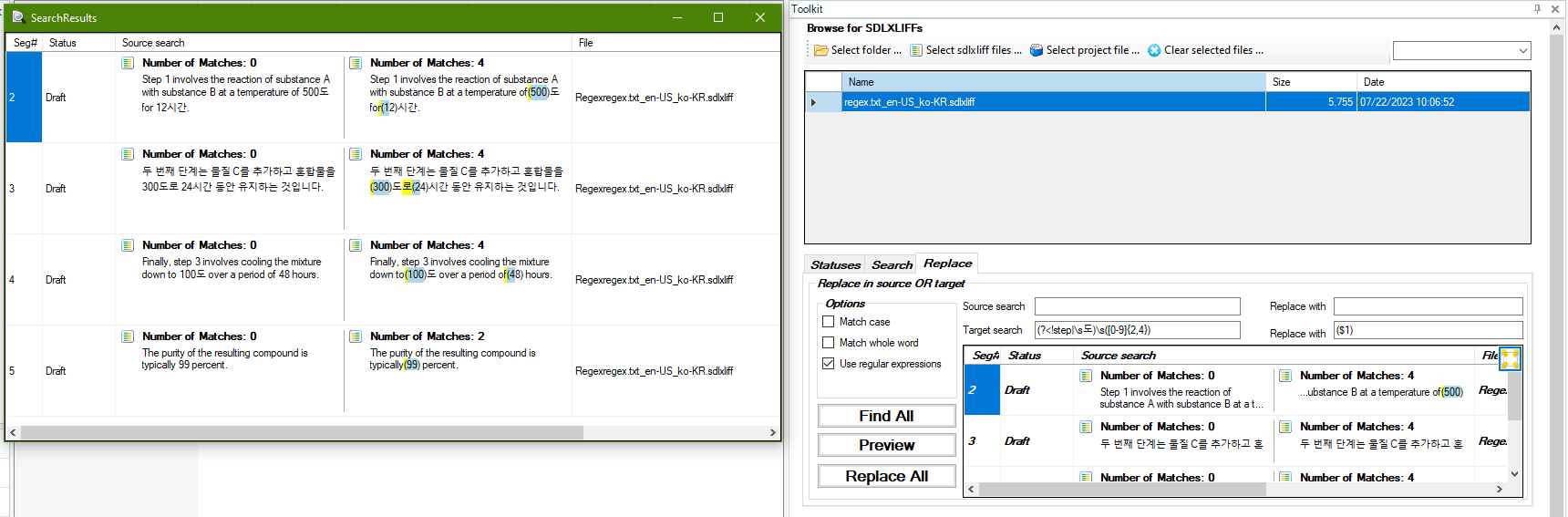
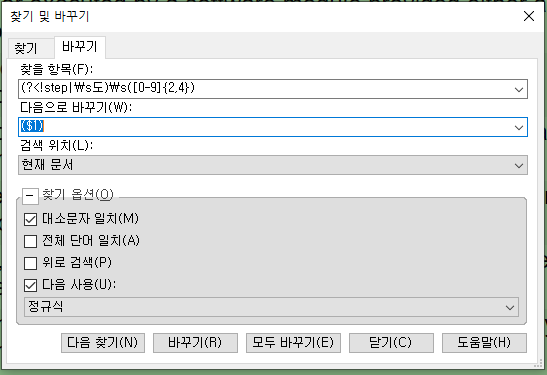
When translating a patent specification, I use the "Negative Lookbehind" of the regular expression in the "Find and Replace" window provided by the edit view of trados studio to perform a find and enclose the found result in parentheses. A simplified example of the regex I'm using is "(?<!step|\s도)\s([0-9]{2.4})" as what to look for and "($1)" as what to replace.
However, after updating to 2022 SR1, the above regular expression pattern is found but not replaced.
Please check this.