Hello,
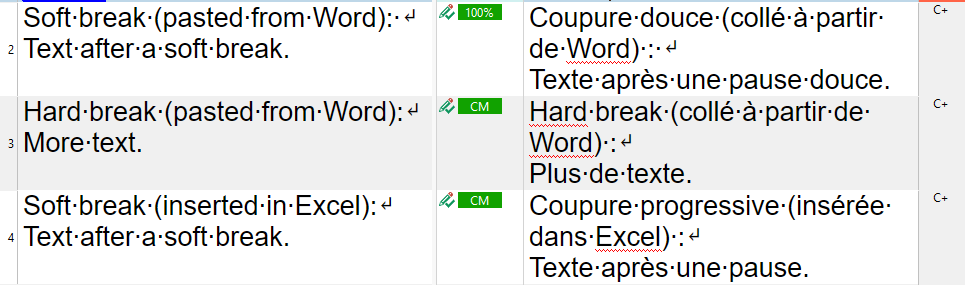
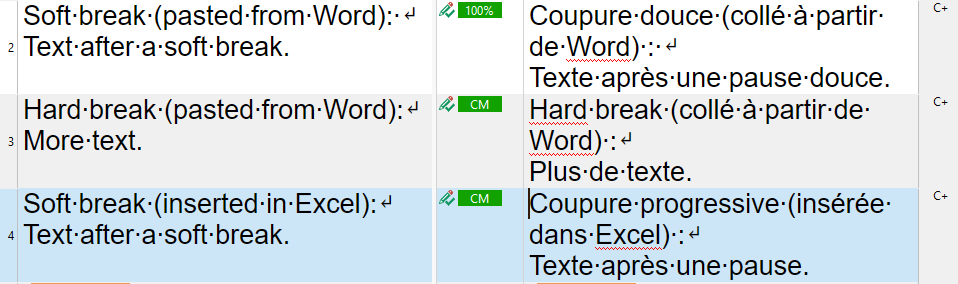
I've been working on a project (with Excel files) where the occurrence of 100% and fuzzy matches is high. However, I realized that when the source strings have hard break lines, Trados Studio 2022 does not identify them automatically and I have to search for the translations manually to paste them into the target text.
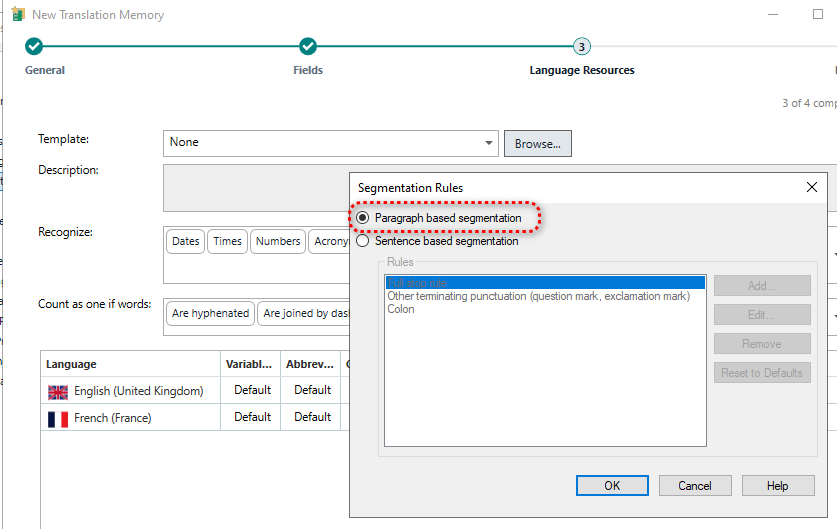
An important information about the TM in question is that it was created by importing a .tmx file generated by memoQ.
Is there any way of getting Trados to recognize these strings automatically without me having to look for the translations?