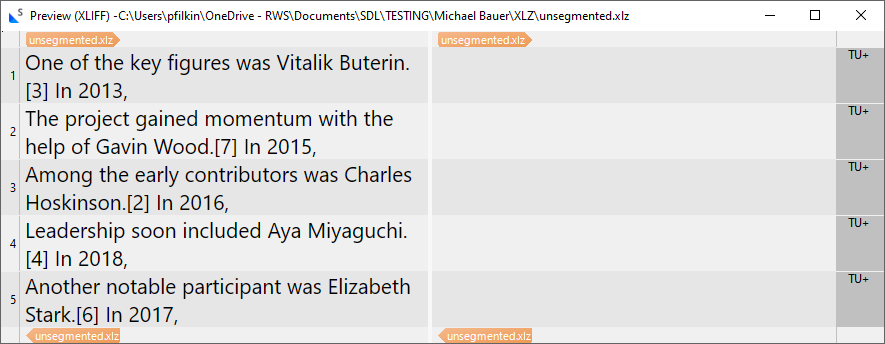
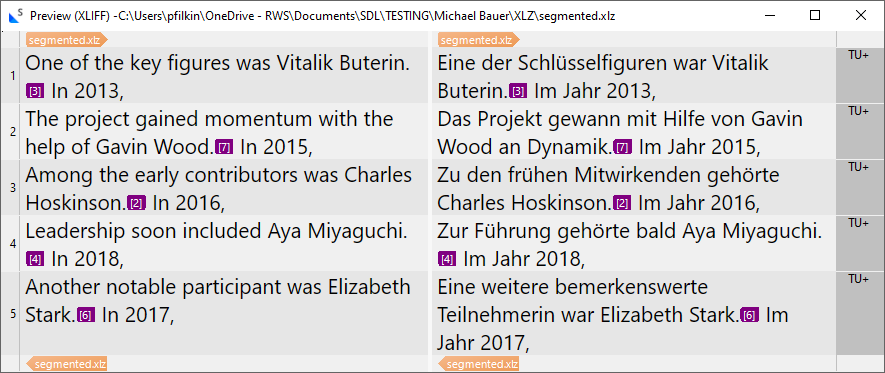
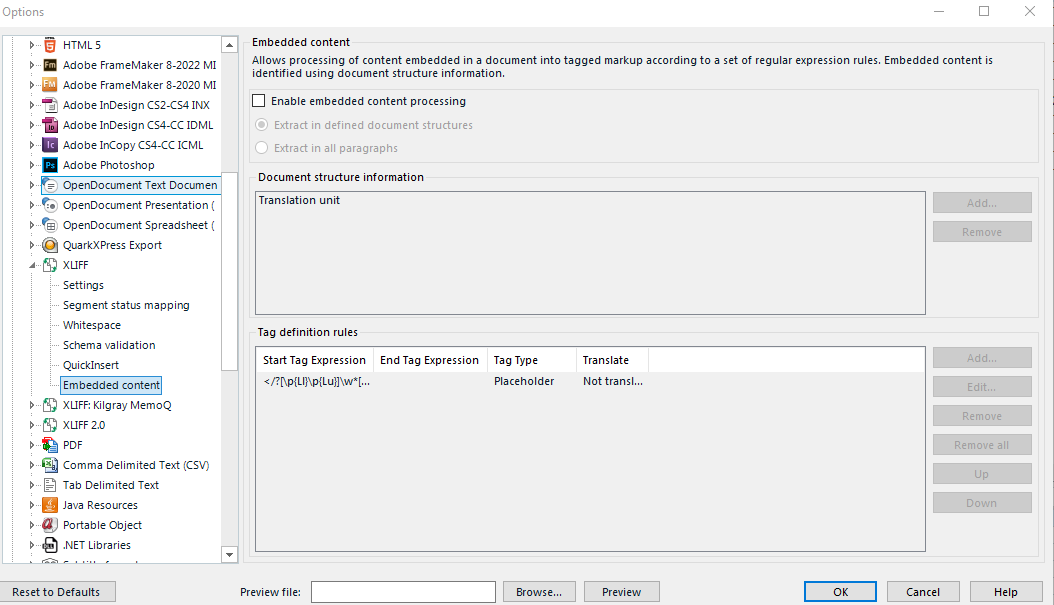
I'm trying to force segmentation in xlz files which contain a lot of strings like this one:
...Joseph Lubin.[5] In 2014,
where Trados doesn't seem to want to segment at the fullstop. I tried a pair of before and after segmentation rules like this:
. .\[*\]
.\[*\] .
but nothing seems to happen. Clearly I'm doing something wrong - again :)