Hello,
I have some documents which contains long sentences of chemical compounds separated with semicolon like "Phosphoric acid; Nitric Acid;..." The segments can reach 6000 characters in some cases. Translators complains about these long segments and even some MT engines refuses to translate that long segments in batch tasks.
I don't want to make " ; " to break segment because in other standard phrases that uses and needs translated in context whit whole context.
Si I tried to make a Segmentation rule in the TM breaking on the segment length and " ; " but it does not work. I have tried a lot of of flavors but maybe is not possible to do what I lookin for.
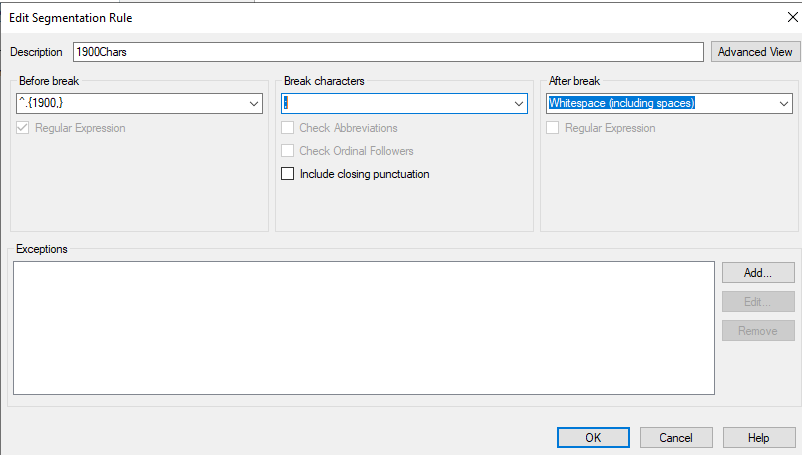
Maybe some of you can help on this?
Thanks in advance.