Hello people,
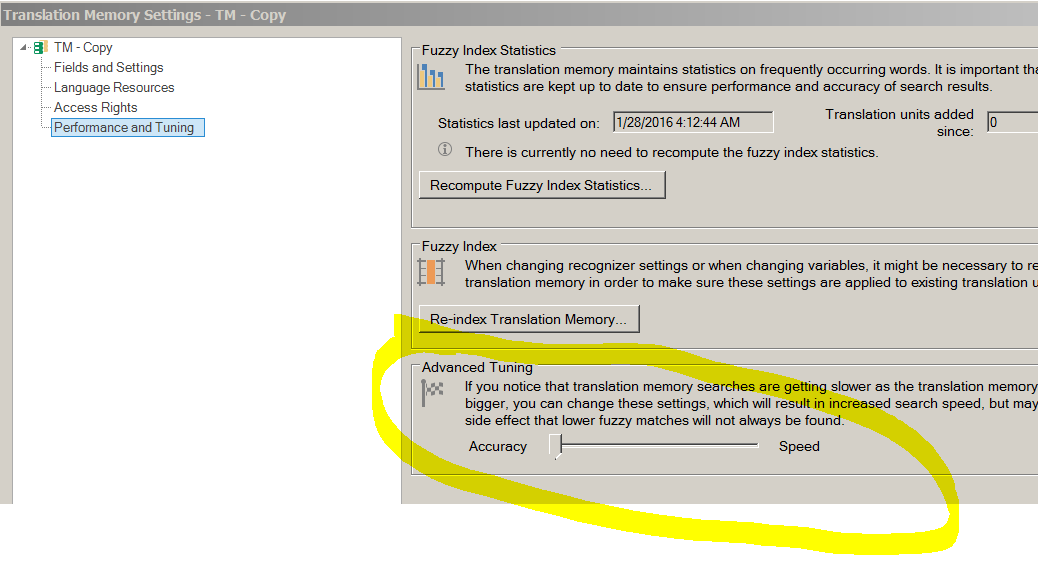
We have got a several different machine translations memories(.sdltm) that's huge at least 180.000 different segments.
the problem is when people that work in our place using our sdltms it take to long time to Pre-translate the projects against our translation memories
I wonder if there is a way to split a sdltm/ is there another solution to handle a huge sdltm?
Thank you in advance.