Hi,
It's likely that this matter has been queried already, but I couldn't find a good match, if so my apologies.
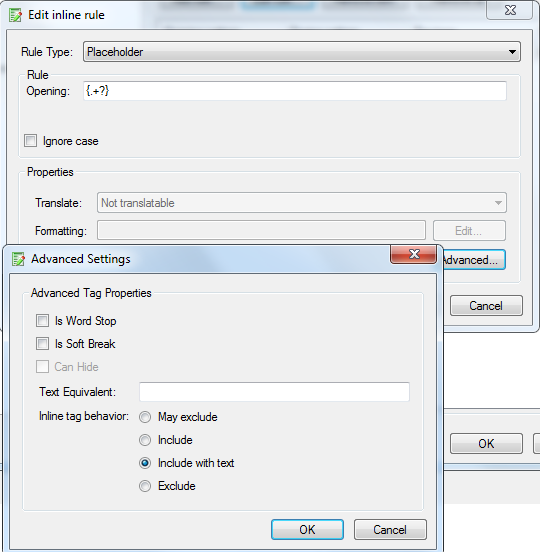
I have the below XML structure, where I want to treat the variables {} as inline tags in Studio (and ideally also newlines \n).
<Term Translate="true">
<Id>Check36VStatus.FailText</Id>
<String>{0} - {1} - Have you turned on the Rider with the key?</String>
<Reference>Text shown when a test step fails for product X</Reference>
<Added>0001-01-01T00:00:00</Added>
</Term>
<Term Translate="true">
<Id>Check36VStatus.SuccessText</Id>
<String>{0} - {1}</String>
<Reference>Text shown when the test step is successfully executed for product X</Reference>
<Added>0001-01-01T00:00:00</Added>
</Term>
<Term Translate="true">
<Id>Check36VStatusTextDescription</Id>
<String>Turn on the machine by turning the key.\n\nImportant, if this test fails then all other tests will fail as well.</String>
<Reference>Description of a UI component for product X</Reference>
<Added>0001-01-01T00:00:00</Added>
</Term>
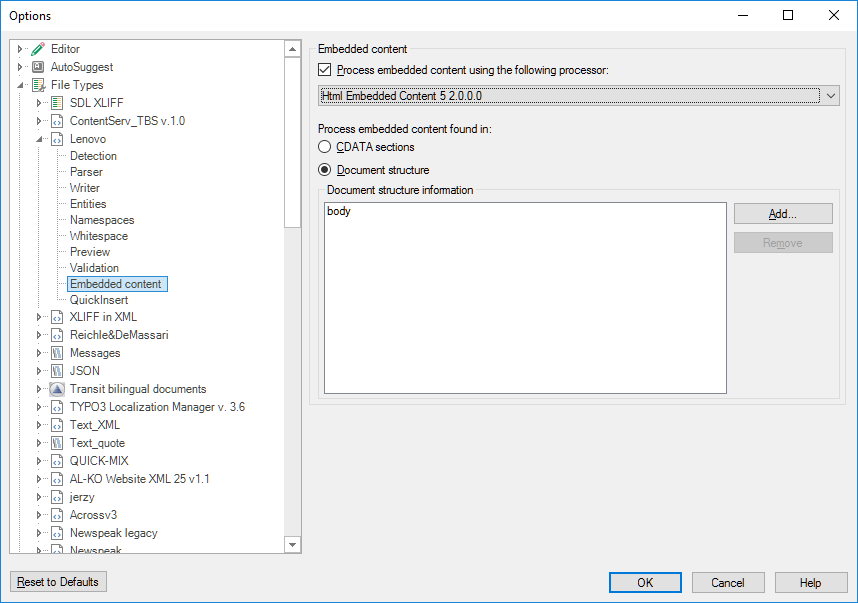
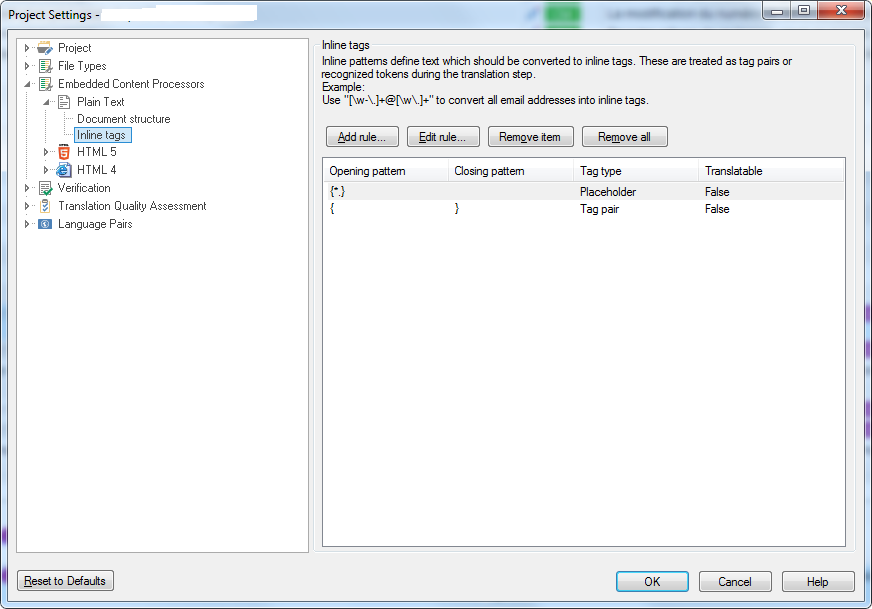
I've tried to use Embedded content with both of the two below settings, but neither causes the brackets to be rendered as tags.
I don't want to use the TM Variable list as I need a stricter enforcement of the rule. Also, I realise that a workaround would be to tag the source text with something like <DNT>{0}</DNT> but I'd prefer not to have to search and replace in the source/final files.
Is the ECP/Inline tags the correct way to address this, and if so what am I doing wrong?
Thanks!
Simon