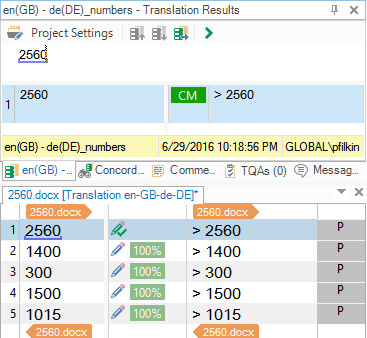
Hello, today I bring a problem with number recognition in the translation memory. I have several segments with numbers that should have been automatically translated (the auto substitution is enable in the TM). Instead I have a 91% match in the memory. The problem is that this match is not a real match.
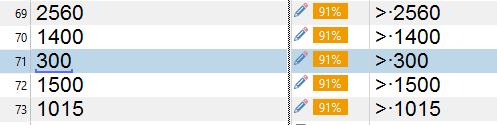
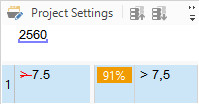
Look at the TU with match in the "Translation results" window. The source segment contains the number "300", in the translation memory I have a 91% match with "> 7.5" (for Trados the only difference is the "> " symbol) and the translation was mixed thus "> 300 ". (I have the same error in all segments).

Why is this happening? Any idea??
Thanks a lot.