

I am getting strange TM match numbers when I use 2 TMs.
When I add a second TM, the number of fuzzy matches increases and the number of 100% matches decreases.
I was under the impression that adding a TM could only improve my matches.
For example, here are the match figures for the job I am currently working on.
Here are the figures with one TM:
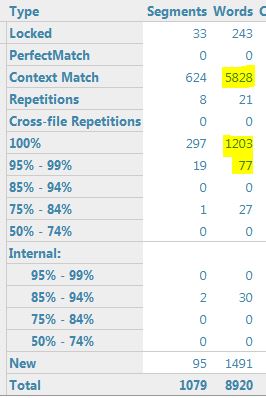
I then add the second TM (with a penalty of 3), and get the following match figures:
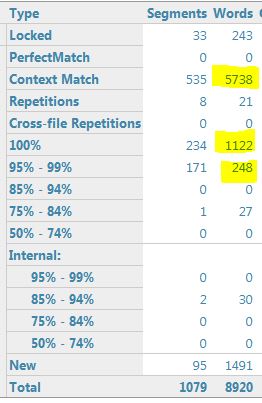
Note that there are 19 segments in the 95%-99% range with 1 TM and 171 segments in this range with 2 TMs.
If I update the project TMs (using both TMs) and then rerun the analysis with just one TM, I get the following:
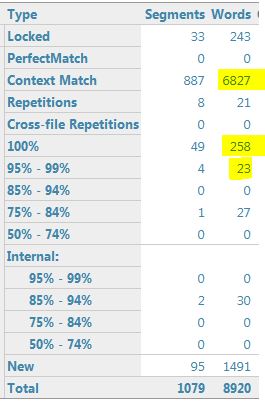
Before the project TMs were updated, there were 17 segments in the 95%-99% range (1 TM) and there are 4 segments in this range after updating (1 TM).
If I add the second TM, I see the following analysis:
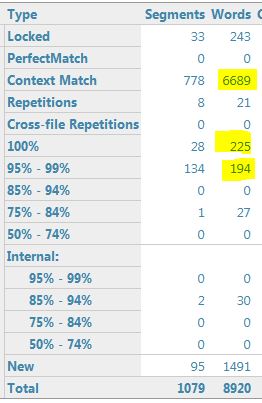
There were 171 segments in the 95%-99% range (2 TMs) before the project TMs were updated and there are 134 segments in this range (2 TMs) after the update.
In summary:
1 TM, before update: 19 segments in 95%-99% range
1 TM, after update: 4 segments
2 TMs, before update: 171 segments
2 TMs, after update: 134 segments
There are two mysteries:
1. Why does adding another TM increase the number of fuzzy matches (decreasing the number of 100% and context matches), both before and after the project TMs are updated ?
2. Why does updating the project TMs change anything? I thought the project TMs were continuously updated during the translation.
Anyone have an idea about what is happening? I have lost a bit of my confidence in the matching algorithm being used.
Regards,
Bruce Campbell
A S A P Language Services

