


I am having trouble understanding the difference between words and tokens in the SDL Trados Studio analysis report.
So far, I always thought that the number of tokens goes up, if I enable more Recognizers (like Numbers, Dates, Times, Acronyms, etc.), and that the number of tokens does down, if I disable Recognizers.
I am currently working on a project involving an Excel file in XML format containing a lot of Embedded HTML and other Embedded Content.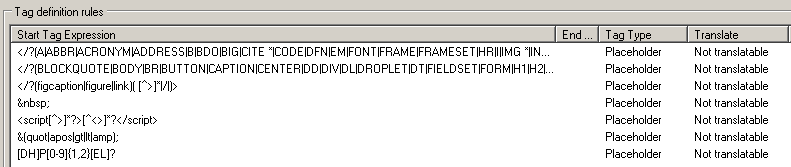
I have the phenomenon that the number of tokens always stays the same, no matter which Recognizers I enable or disable in the project settings (Language Pair -> Auto-substitution) and TM settings (Fields and Settings -> Recognize).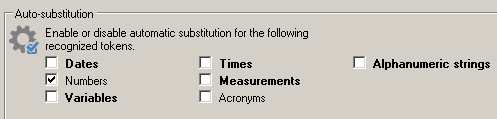
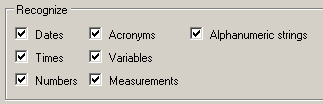
But the number of tokens varies greatly depending on whether my TM is enabled or disabled.
TM enabled: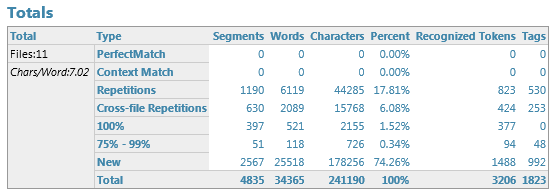
TM disabled: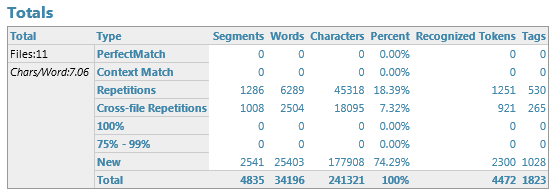
Any feedback on this phenomenon would be helpful.
