I thought it would be helpful to kick off this thread as we are seeing a few questions in different places about upLIFT and whether this is the same as Lift which was the basis of this technology when Kevin Flanagan first introduced it.
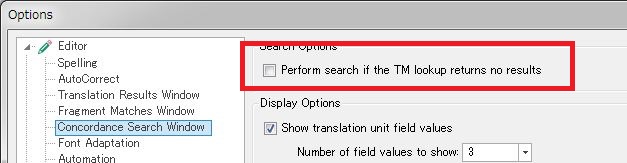
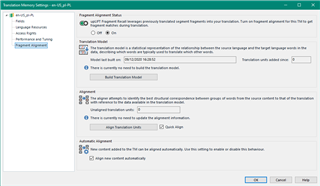
So my first question would be how many TUs are needed in your Translation Memory to be able to upgrade it for full upLIFT capability with fragment matching and fuzzy match repair? I read that Lift could do this from a very small number of TUs yet upLIFT does seem to require a bigger starting point.
What questions do you have?
Regards
Paul
Paul Filkin | RWS
Design your own training!
You've done the courses and still need to go a little further, or still not clear?
Tell us what you need in our Community Solutions Hub