

Hi community:
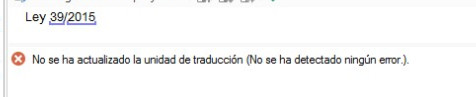
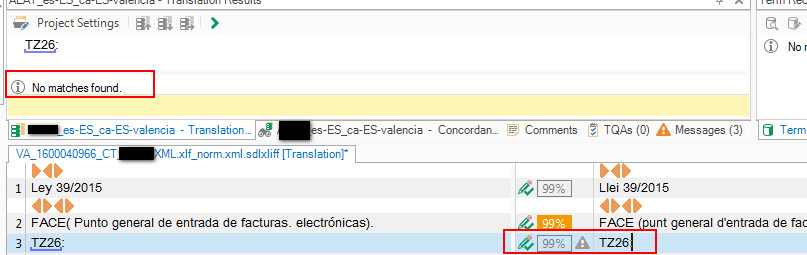
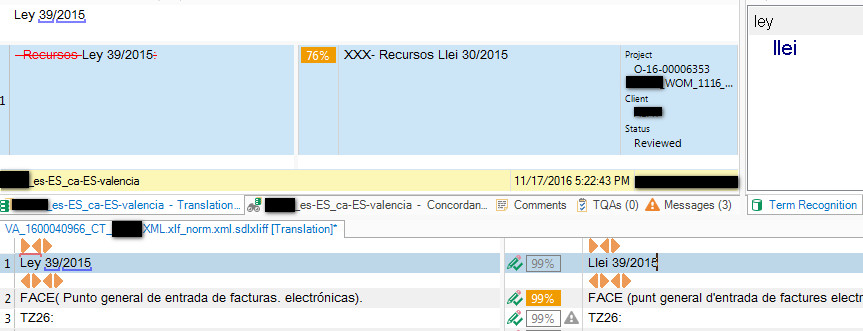
I am not sure if this is a normal behaviour for a TM updating. The affected translation memory refuses to update segments that only contain an alphanumeric string, like TZ26 for example, unless I translate them different. If source and target remain exact (as they should), the segment is not updated in TM. The same happens with other short segments having a combination of a recognized term and a date, for example Ley 39/2015. In termbase I do have ley->llei (valencian).
A warning is shown, reading "Failed to update translation unit. No errors found" (see image, my message in Spanish)
It is not a global problem with updating. In fact, all other segments are correctly updated.
This behaviour is not convenient since those segments are common and we need to 100% pretranslate them. Also analysis may be affected, I presume..?
I tried reindexing - no success.
I'm attaching some screenshots to illustrate the problem.
The translation memory languages are Spanish->Valencian. Hopefully it's not a culture-related problem?
Many thanks in advance,
Almudena

