Was playing with the subtitling app from the AppStore.
Is my understanding correct that this scenario is not covered? Is SDL working on a solution for this problem? Let me explain:
Consider my 7028. Common troubleshooting tips_b.srt.zip. As you can see, entire sentences are actually split among several timecode segments:
1
00:00:00,110 --> 00:00:03,152
The missing components detail
instruments that are not present
2
00:00:03,152 --> 00:00:06,870
in the ECU test system but were
part of the original
3
00:00:06,870 --> 00:00:10,588
configuration shipped by NI.
You will want to ensure that
If I wanted to translate this automatically using MT, it would be highly beneficial to actually send the MT engine an entire sentence, rather than snippets of incomplete sentences. Same thing if I want to hope to get useful leverage from other types of documents translated using CAT tools.
So ideally, I would want my SRT tool to AUTOMATICALLY extract TUs that would look like this:
- The missing components detail <LF/> instruments that are not present <M/> in the ECU test system but were <LF/> part of the original <M/> configuration shipped by NI.
- You will want to ensure that ...
where <LF/> indicates a line break within a timecode, and <M/> indicates that several timecodes had to be merged to form a full sentence.
And then, put this back correctly when generating the target like this (in French)"
1
00:00:00,110 --> 00:00:03,152
Les composants manquants détaillent
les instruments qui ne sont pas présents
2
00:00:03,152 --> 00:00:06,870
dans le système de test pour ECU mais
qui faisaient partie de la configuration originale
3
00:00:06,870 --> 00:00:10,588
livrée par NI.
Vous devriez vous assurer que...
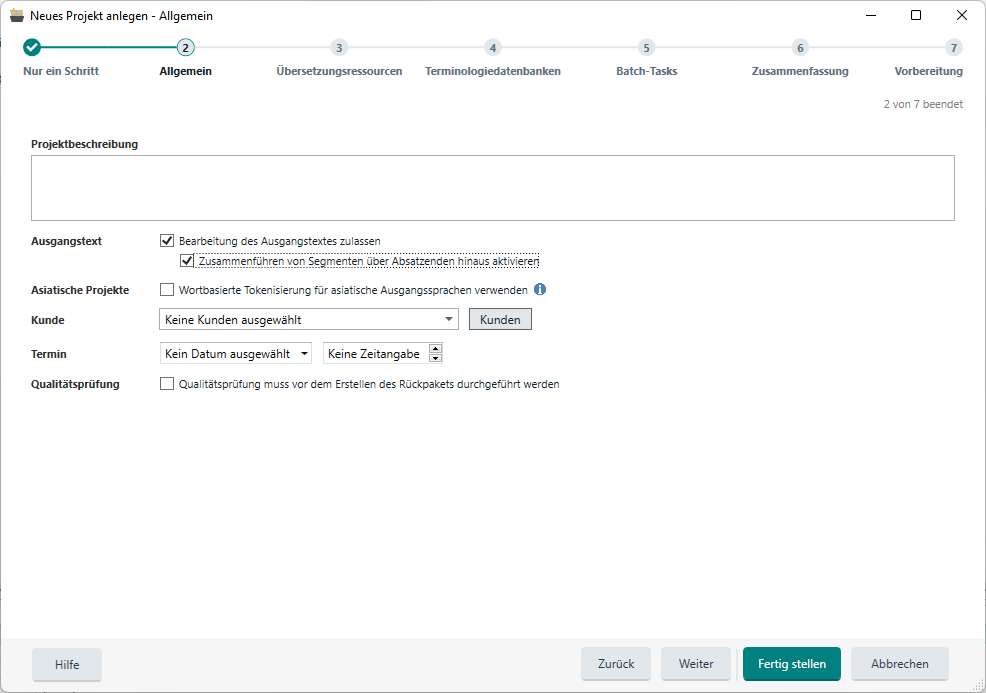
Today, you can only do that by doing a MANUAL merge segment if you have enabled the "Enabling merging of segments across paragraphs". and even that doesn't work well when you generate targets, as you end up with empty time codes, while others have the full sentence.
I would REALLY like to see a solution that automatically merges the sentence snippets until they form a logical sentence (using typical segmentation rules and maybe a little bit of AI magic) and splits it back intelligently into the target timecodes.
I hope my request makes sense.