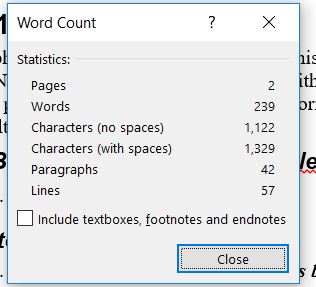
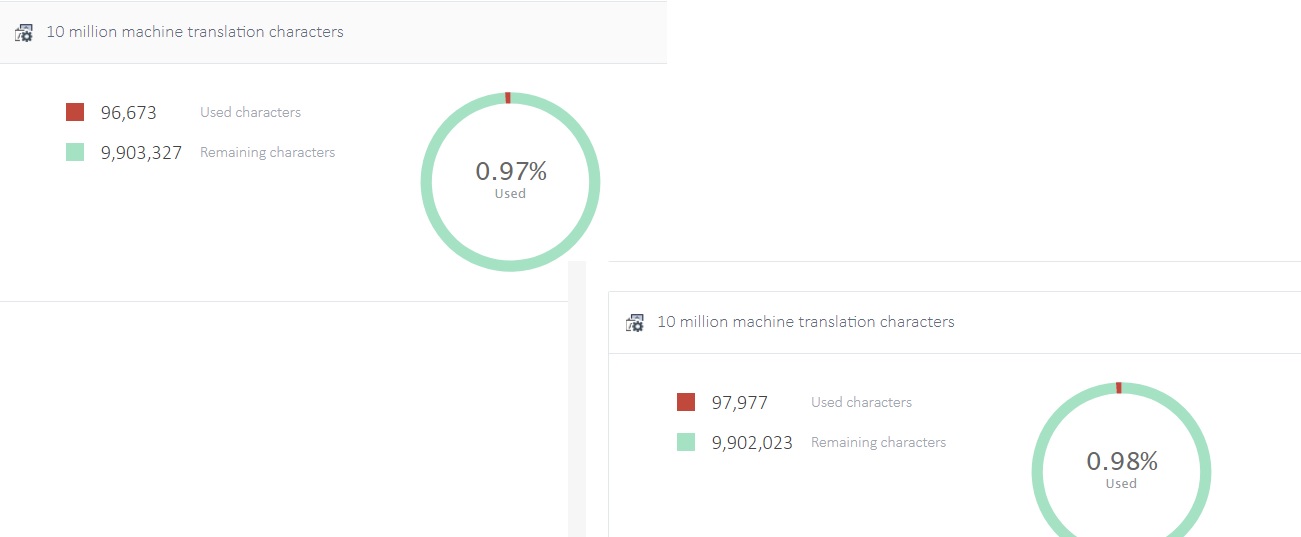
One of my colleagues used this MT last month but her account was quickly blocked as she reached the limit. However, she knows she hasn't actually translated that much using the MT.
So I did a simple test: I ran a file, one segment at a time through the MT while checking my account open. To my surprise, my account shows I translated 6416 characters, while a count in Word of the same gives me 1644 characters (no spaces) and 1926 characters (with spaces)...
So... I do wonder. How does the algorithm calculate the number of characters? No wonder why my colleague reached so easily the limit!