Hey!
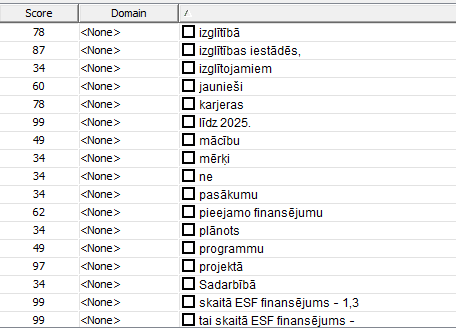
Somehow MultiTerm 2021 Extract does not decode Latvian language code (but it tells in the description it does) and I get gibberish results:
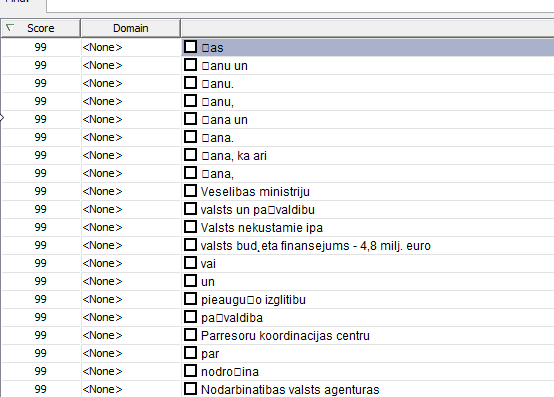
Is there any way how to fix this? As I'm using this tool to extract the terms, but this issue makes it useless.
Please let me know.
Kind regards
Kaspars Rutkis
Generated Image Alt-Text
[edited by: Trados AI at 2:09 PM (GMT 0) on 5 Mar 2024]