


Hi all
What is recommended TermBase structure:
1. in different domain-specific sdltb files
I this case I am getting lost among many files and loosing track whenever I need them connected to Trados
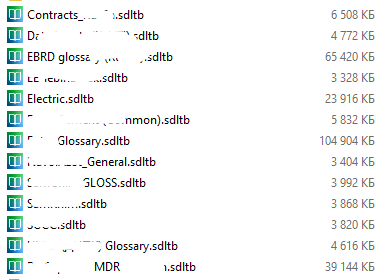
or
2. in the same single sdltb file
in this case I feel the sdltb file gets oversized if I use fields to specify my language domain for each entry, plus it takes more time for manual manipulations in Excel column
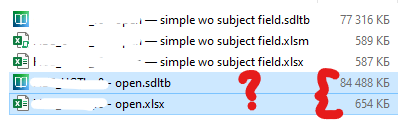
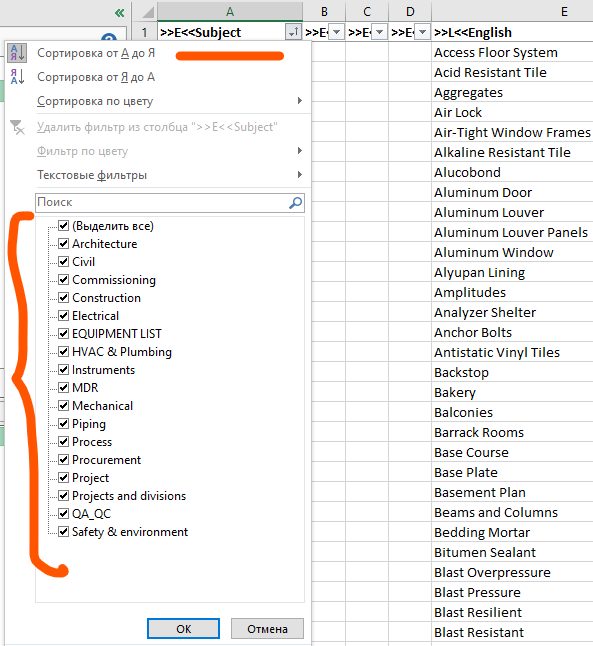

Are there any recommendation on how to maintain/keep termbases more efficient in terms of minimum files size / faster search with better translator-friendly approach?
Please share, thank you
Generated Image Alt-Text
[edited by: RWS Community AI at 6:44 PM (GMT 0) on 14 Nov 2024]


