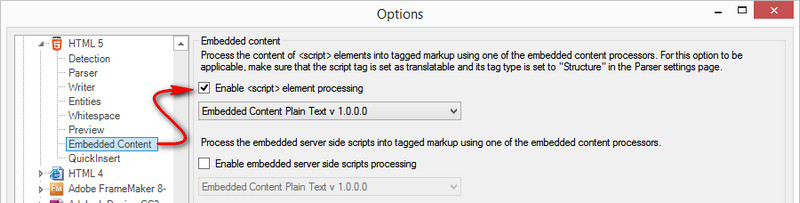
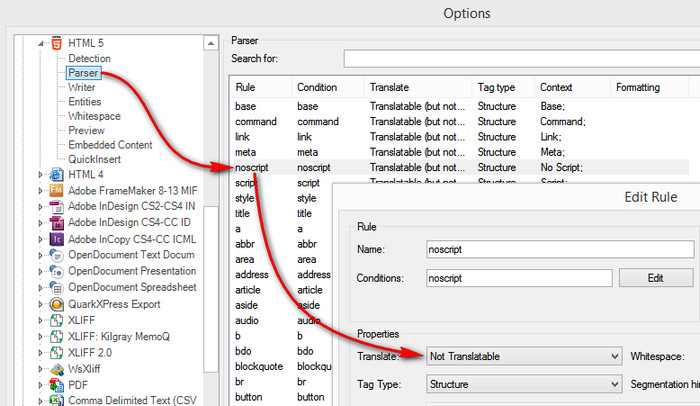
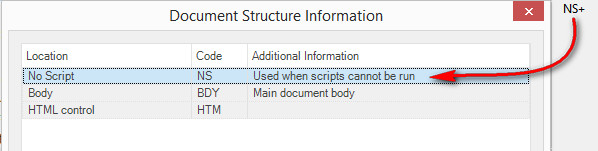
I have a problem with my text. I have imported the file and I have some segments like this.
'<p style="margin:0;padding:0;border:0;"> <img src="track.adform.net/.../ width="1" height="1" alt="" /> </p>'
I already replaced < and > with notepad and used parser and attribute box for meta.
What can I do with these? Thanks