


翻訳メモリにおいて、「1つの原文に対して複数の対訳が存在する」ケースだけを検索する方法はありますでしょうか?
RWS Community
翻訳メモリにおいて、「1つの原文に対して複数の対訳が存在する」ケースだけを検索する方法はありますでしょうか?

Hiromi Takahashi 様
投稿いただきありがとうございます。
例えば、このようなTMの内容で原文が重複している翻訳単位(TU)を抽出したいとします。
ここでは、1と2、および3と5のTUがそれぞれ同じ原文で重複しています。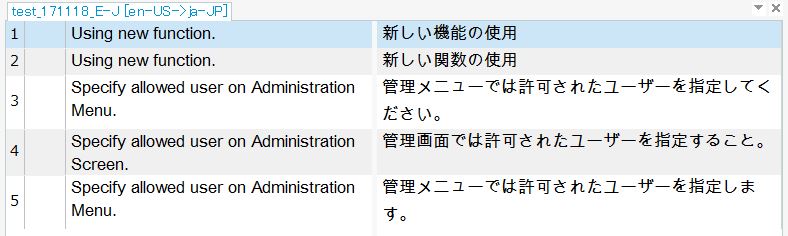
1. [翻訳メモリ] ビューよりTMを開きます。
2. [検索の詳細]ウィンドウの[検索の種類]で[重複している可能性のあるもののみ検索]を選び、[検索の実行]をクリックします。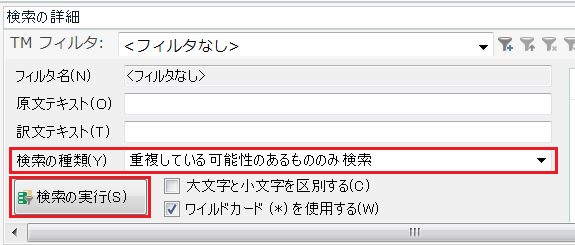
3. 原文の重複したTUが表示されます。ここで注意が必要なのですが、1ページに付き1件の重複しか表示されません。次の重複を確認したい場合、[ナビゲーション]より[次のページ]をクリックします。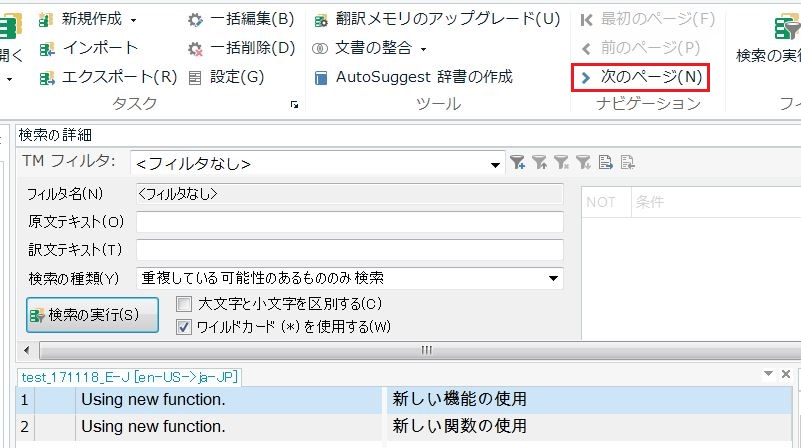
4. 次のページに移行すると、別件の重複が表示されます。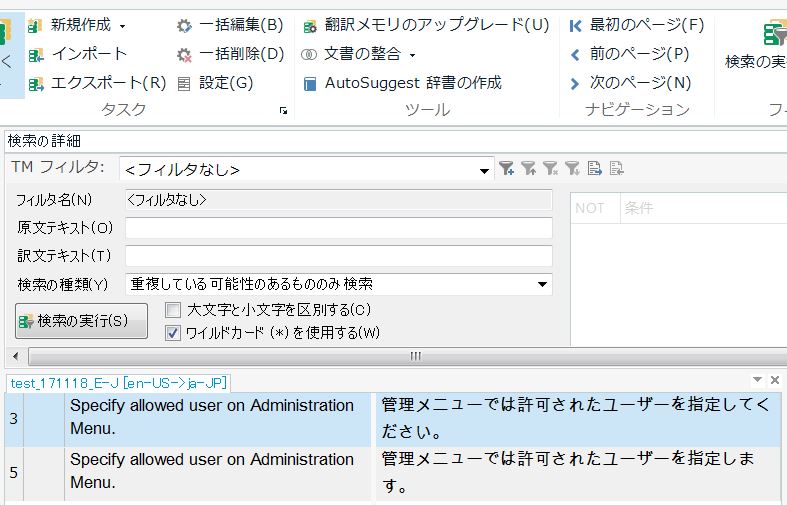
Hiromi Takahashi 様
投稿いただきありがとうございます。
例えば、このようなTMの内容で原文が重複している翻訳単位(TU)を抽出したいとします。
ここでは、1と2、および3と5のTUがそれぞれ同じ原文で重複しています。
1. [翻訳メモリ] ビューよりTMを開きます。
2. [検索の詳細]ウィンドウの[検索の種類]で[重複している可能性のあるもののみ検索]を選び、[検索の実行]をクリックします。
3. 原文の重複したTUが表示されます。ここで注意が必要なのですが、1ページに付き1件の重複しか表示されません。次の重複を確認したい場合、[ナビゲーション]より[次のページ]をクリックします。
4. 次のページに移行すると、別件の重複が表示されます。
Hiromi Takahashi 様
機能要望の件、承りました。弊社内で検討させていただきます。
翻訳作業中の文章における訳文の不統一は、QA Checker 3.0の「不整合」の項目にてチェックすることができます。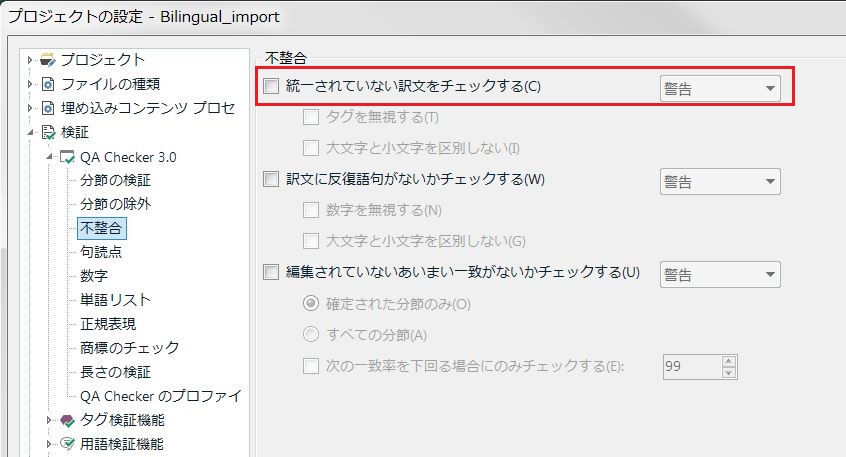
こちらの項目を有効にし、エディタ画面で「検証(F8)」を実行しますと、同一の原文に対して訳文が統一されていない場合にメッセージが表示されます。こちらも併せてご利用ください。