

整合で、訳文(邦文)の全角ピリオドで文が切れないように取り込む設定にするにはどうしたらよいでしょうか。
分節規則のterminating punctuationの終了文字から全角ピリオドを削除してみたり、規則の例外を追加してみたりしましたが、文ではなく段落で分節化されるようになってしまいます。
整合で、訳文(邦文)の全角ピリオドで文が切れないように取り込む設定にするにはどうしたらよいでしょうか。
分節規則のterminating punctuationの終了文字から全角ピリオドを削除してみたり、規則の例外を追加してみたりしましたが、文ではなく段落で分節化されるようになってしまいます。

Jesse Good様
まず原文が英語、訳文が日本語で、段落ではなく文に基づく分節化を希望しています。
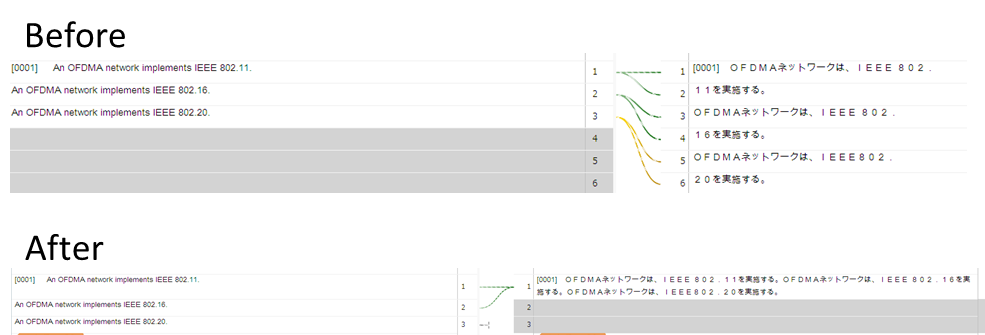
整合する際に、訳文に全角ピリオドがあるとそのピリオドで分節化されてしまい原文と紐づける作業が必要となります(before)。
そこで、整合文書を取り込む翻訳メモリの分節規則(日本語)の「terminating punctuation」から、全角ピリオドを削除したり、規則の例外を追加したりしてみましたが、
分節規則に手を加えると、訳文のみ段落での分節化となってしまいます(after)。
この例ではピリオドで分節化されていても正しく紐づけられているので問題ないですが、量が多かったりすると紐づける作業にかなり時間がかかってしまいます。
全角ピリオドで分節化されずに取り込める方法がありましたらご教示いただけますと幸いです。
Jesse Good様
まず原文が英語、訳文が日本語で、段落ではなく文に基づく分節化を希望しています。
整合する際に、訳文に全角ピリオドがあるとそのピリオドで分節化されてしまい原文と紐づける作業が必要となります(before)。
そこで、整合文書を取り込む翻訳メモリの分節規則(日本語)の「terminating punctuation」から、全角ピリオドを削除したり、規則の例外を追加したりしてみましたが、
分節規則に手を加えると、訳文のみ段落での分節化となってしまいます(after)。
この例ではピリオドで分節化されていても正しく紐づけられているので問題ないですが、量が多かったりすると紐づける作業にかなり時間がかかってしまいます。
全角ピリオドで分節化されずに取り込める方法がありましたらご教示いただけますと幸いです。

Yuki Kitaji様
ヘルプによると終了文字は現在のところかなり限られているようです。
作業時間の観点からは、次のような臨時処理をお勧めします。
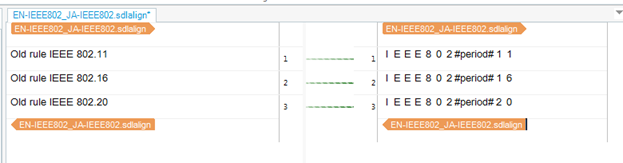
全角ピリオドを何か特有なもの(例えば、#period#)に置き換えて整合を行い、SDLXLIFFとして保存
SDLXLIFF を開いて、#period#を全角ピリオドに置き換えて、SDLXLIFFを保存
翻訳メモリをSDLXLIFFで更新
ほかの方法など見つかりましたら、お知らせください。ご報告お待ちしております。
Studioの整合ファイルや置換機能などが現在不安定なので、以下の方法を追加しました。
翻訳メモリが更新された後、整合に使った英語のファイルをStudioで開き、翻訳メモリで翻訳
置換機能が現在不安定なので、まず#period#を検索、検索が機能した後、置換ができるようになります。
置換が終わったところで、翻訳メモリを更新。
