


I'm wondering if I could address the community and staff about some issues I am having with fuzzy matching in the editor.
I'm actually migrating here from smartCAT, which is a CAT platform with a lot of rigidity in terms of word processing that ultimately became a deal breaker for the kind of academic work that I want to do. I am still on the TRADOS 30 day trial and seeing how it compares. So far I am very happy with the additional flexibility of TRADOS and it is fullfiling all my word processing needs (making academic annotations was key here, which I was able to finagle by exporting comments in the .docx and then converting them into endnotes with a macro).
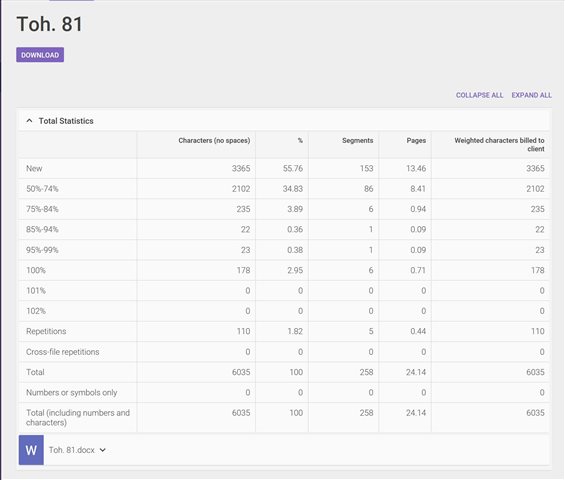
However, now I am comparing the fuzzy matching capabilities between smartCAT and TRADOS and I'm not really impressed with the initial statistics I'm getting. Here pasted below are two screen shots of the statistic reports comparing smartCAT and TRADOS, these were done with the exact same file, segmentation, and TM bank (I currently have .tmx files from 32 projects), on both projects I set the minimum fuzzy matching setting to 50%:
smartCAT (freelance account 5/4/2019) :
SDL Trados 2019 SDR1 - 15.1.2.48878
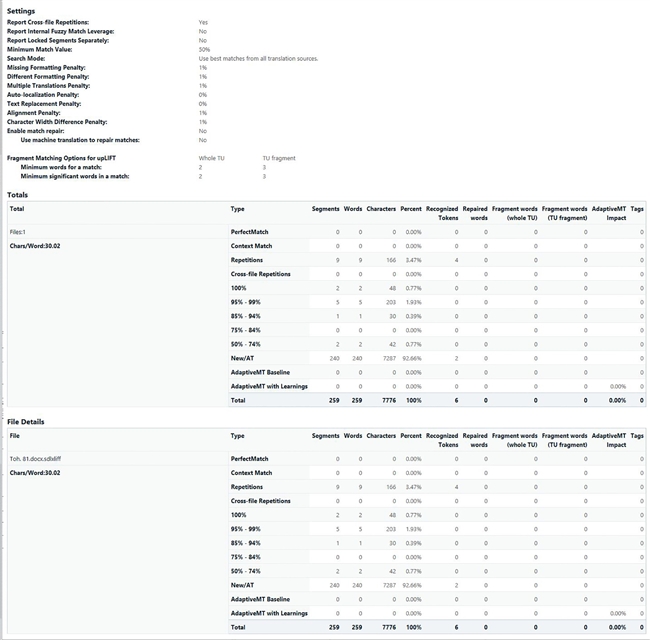
As you can see TRADOS is registering 50%+ matches, but not nearly as many as smartCAT. So this isn't looking very good in TRADOS, for me the fuzzy matching capablities are really the essential value for using any CAT tool in the first place, but I'm new to the platform and I know there are a lot more options and variables in TRADOS that I'm not familiar with so I'm wondering if there is a way to boost these stats. I am wondering:
(1) If there is a way I can adjust my settings and variables in way to get more matches (they are both set to 50% so I know it's not that)
(2) Could there be a particular issue with the Tibetan script that is giving me a low match rate? Tibetan is an uncommon digital language, so I'm used to seeing a lack of support for the script across various platforms.
(3) Are there any updates, or add-ins that could give augment these fuzzy match capablities, particularly if this is an issue specific to the Tibetan script? I tried updating to 2019 SDR1 - 15.1.2.48878 and updating all the TMs but I'm getting the same stats as before.
Here is one example for why I'm not getting as good matches in TRADOS vs. smartCAT:
This is a phrase in my test document:
བཅོམ་ལྡན་འདས་རྒྱལ་པོའི་ཁབ་ན་བྱ་རྒོད་ཀྱི་ཕུང་པོའི་རི་ལ་དགེ་སློང་སྟོང་ཉིས་བརྒྱ་ལྔ་བཅུའི་དགེ་སློང་གི་དགེ་འདུན་ཆེན་པོ་དང་ཐབས་ཅིག་ཏུ་བཞུགས་ཏེ།
བཅོམ་ལྡན་འདས་རྒྱལ་པོའི་ཁབ་ན་བྱ་རྒོད་ཀྱི་ཕུང་པོའི་རི་ལ་དགེ་སློང་སྟོང་ཉིས་བརྒྱ་ལྔ་བཅུའི་དགེ་སློང་གི་དགེ་འདུན་ཆེན་པོ་དང་ཐབས་ཅིག་ཏུ་བཞུགས་ཏེ།
This is a very close phrase in one of my TMs:
བཅོམ་ལྡན་འདས་རྒྱལ་པོའི་ཁབ་ན་བྱ་རྒོད་ཕུང་པོའི་རི་ལ་དགེ་སློང་སྟོང་ཉིས་བརྒྱ་ལྔ་བཅུའི་དགེ་སློང་གི་དགེ་འདུན་ཆེན་པོ་དང་། བྱང་ཆུབ་ སེམས་དཔའ་ཁྲི་དང་ཐབས་ཅིག་ཏུ་བཞུགས་ཏེ།
In smartCAT this gets a 84% hit, but it is completely missed by TRADOS and doesn't even register as a 50% match. I'm looking through all my TM matches in TRADOS and it only seems to hit when there is a match via a continuous string with no breaks in the middle, but strings with more than one variable substrings, like the one above are not registering. From examples I've seen, it seems like TRADOS would catch the strings with more than one variable substrings if it was Spanish, but perhaps because Tibetan doesn't have spaces between words (it only places dots between syllables) the results aren't so great. Is there anyway to improve this?
Thanks so far, to all the staff and community who have been very patient answering my questions. I would love to make this work, as everything else in TRADOS is really excellent. I would just like to mention that I'm also reviewing the platform for an academic organization I work for that focuses on Tib-Eng tranlsation, if I can confirm a good setup here, I'll be recommending it to several dozen other translators, but this low match rate could really be a deal breaker for me.
Best wishes,
-Celso
Generated Image Alt-Text
[edited by: Trados AI at 4:26 PM (GMT 0) on 28 Feb 2024]


