


Hello everyone,
Alphanumeric Strings Recognition feature is for sure one of the most useful feature around in Trados Studio.
Sadly it recognizes as an Alphanumeric String even the [0-9]-[A-Z]+ regular expression, producing wrong results as you can see below:

The suggestion comes from a correct TU in the TM:
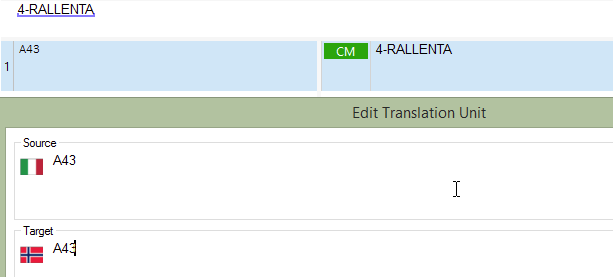
I tried unticking the "Count as one if words are joined by dashes" option, with no results.
This also produces wrong fuzzy suggestions, making the translation tricky and the word count unfair.
How do you manage this issue? Has anyone a good solution?
2 Years ago a nice idea was proposed: Being able to modify the regular expressions used for Alphanumeric String Recognition in each TM the same way we do for Segmentation Rules.
Thank you to anyone willing to give suggestions and advices.
Generated Image Alt-Text
[edited by: Trados AI at 6:45 PM (GMT 0) on 28 Feb 2024]



