Bonjour,
Notre IHM doit être traduite dans différentes langues. Pour l’instant elle est traduite en français, anglais et allemand. Nous souhaitons la traduire en italien , portugais, espagnol et danois.
Les ddl de l’IHM injectée dans App translator nous génère des fichiers.xlf .
Je crée un projet pour chaque traduction (les dll source sont en US et je veux les traduire en FR ou SP). Pour chacun des projets , je fais les manipulations suivantes :
J’importe le fichier issu d’Apptranslator dans sdltrados (par exemple spanish-export 27-4-20..xlf)
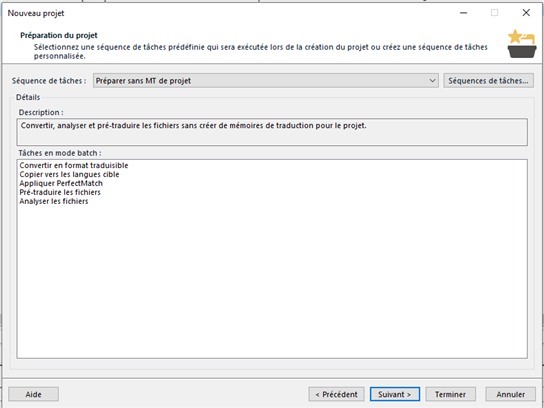
Je fais « préparer sans MT de projet »
J’ai une mémoire dédiée à ce projet ainsi qu’une base terminologique commune a tous mes projets
Cela génère un fichier. Sdlxliff (par exemple spanish-export 27-4-20..xlf.sdlxliff)
Lorsque j’ouvre le fichier avec l’éditeur je n’ai pas le même nombre de segments selon la langue traduite.
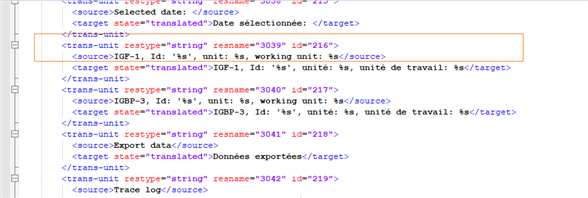
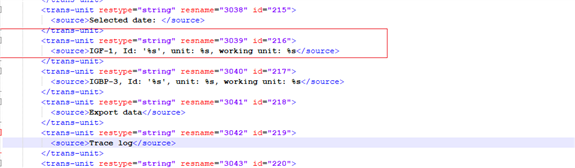
En effet pour le français (et l’anglais et l’allemand qui ont déjà été traduits) où tous les segments étaient traduits j’ai 443 segments alors que pour l’espagnol (l’italien, portugais et le danois) j’ai 500 segments et pourtant le fichier ddl original (US) est le même
Il semblerait que pour l’espagnol et les autres langues non traduites, sdltrados crée un segment pour certains changement de caractères.
Ci-dessous ce qui a été généré pour le francais

En ce qui concerne l’espagnol, voici ce que cela génère

Avec ma collègue informaticienne nous avons essayé de comprendre ce phénomène…
Quand on ouvre le fichier avec Notepad++, on a pour le français
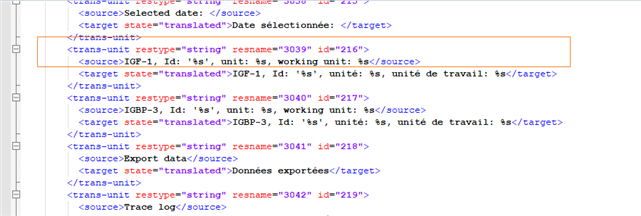
Et pour l’espagnol
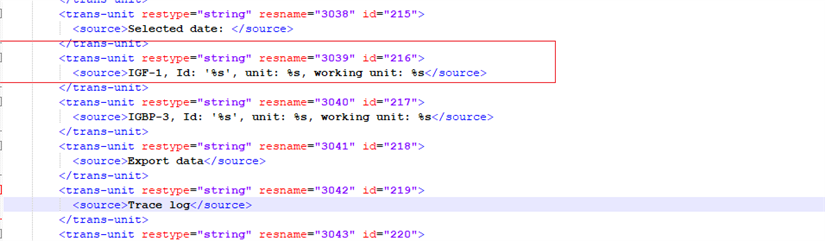
Hormis le fait que ça ne soit pas traduit, les fichiers originaux avant de préparer le fichier traitent l’information de façon similaire.
Il semblerait que lors du traitement des fichiers par SDltrados en fichier.xliff, des segments sont séparés en plusieurs segments (ce qui aboutit au nombre de segments différents selon les langues).
Y a-t-il une case à cocher ou un traitement particulier pour avoir le même nombre de segments dans les différentes langues ? car il se pourrait que cela génère des problèmes au moment de réinjecter les fichiers traduits dans notre logiciel et que le rendu dans l’IHM ne corresponde pas à la traduction désirée.
Merci d'avance pour votre aide
Generated Image Alt-Text
[edited by: Trados AI at 9:17 PM (GMT 0) on 28 Feb 2024]