


Hi, I would appreciate if anyone can help me with the following problem:
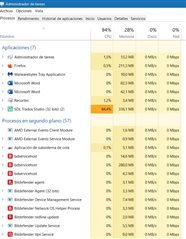
I am working in a project (single file, single TM, two TB (main one online), and whenever I came into a project with several chemical names, Trados starts to use approximately 90 % of CPU and I have to wait several minutes for each segment. Until now, it had worked fine with projects involving numerous files, TMs and TBs.
I would appreciate any help.
Thanks in advance.
Pablo Mones
Project characteristics:
- Words: 39,626
- Segments: 2,222
- TM: 1,347 units
PC:
- Windows 10 64 bit
- Memory: 16 GB
- Processor speed: 4.19 GHz
- Processor: AMD A8-5600K
- Antivirus: Bitdefender
- Antimalware: Malwarebytes
Example of chemical compound (for confidentiality reasons I just made it, it is not a real one from the file, but they are all like this)
R-2-allyl-1-(7-ethyl-7-hydroxy-6,7-(7-ethyl-7-hydroxy-6,7-dihydro-5H-cyclopenta[b]pyridin-2-yl)-6-((3-methyl-4-phenyl)amino)-1,2-dihydro-3H-pyrazolo[3,4-d]pyrimidin-3-one
Generated Image Alt-Text
[edited by: Trados AI at 9:43 PM (GMT 0) on 28 Feb 2024]



