Hi!
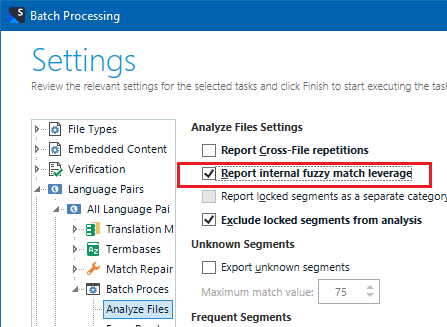
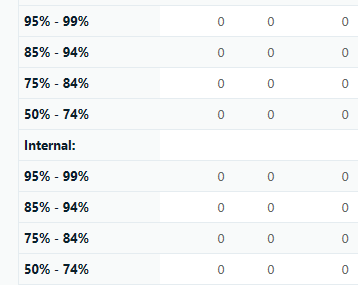
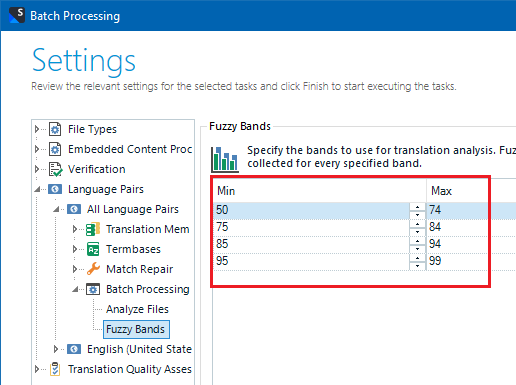
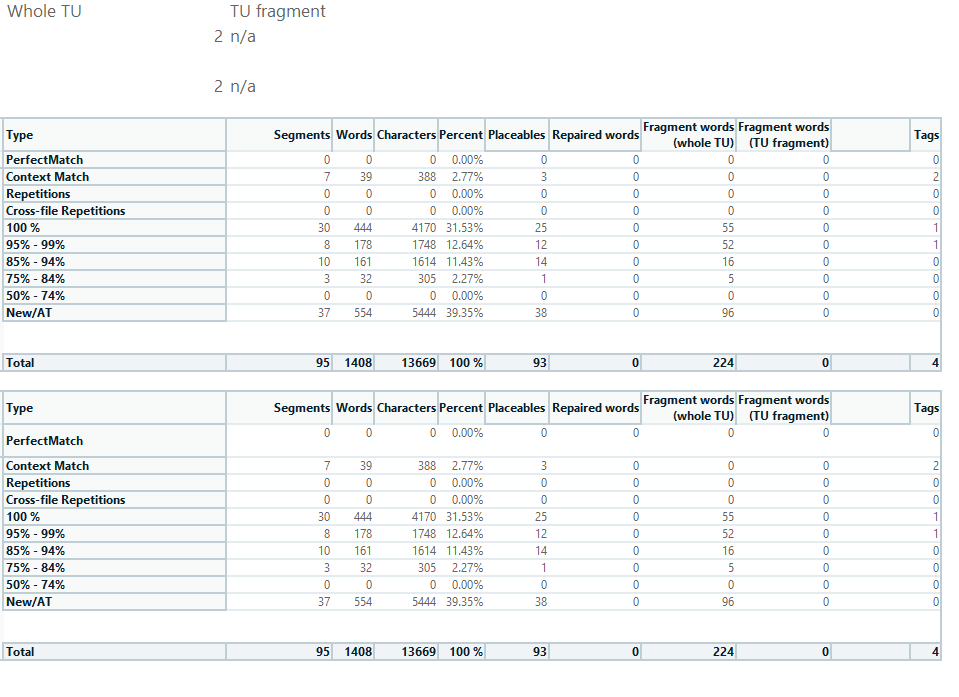
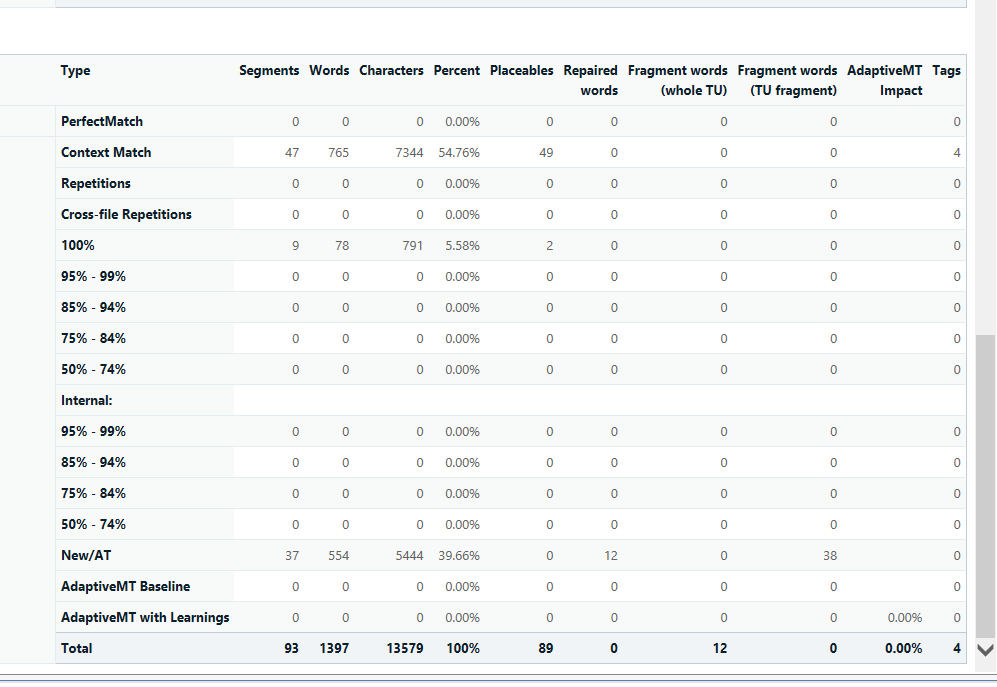
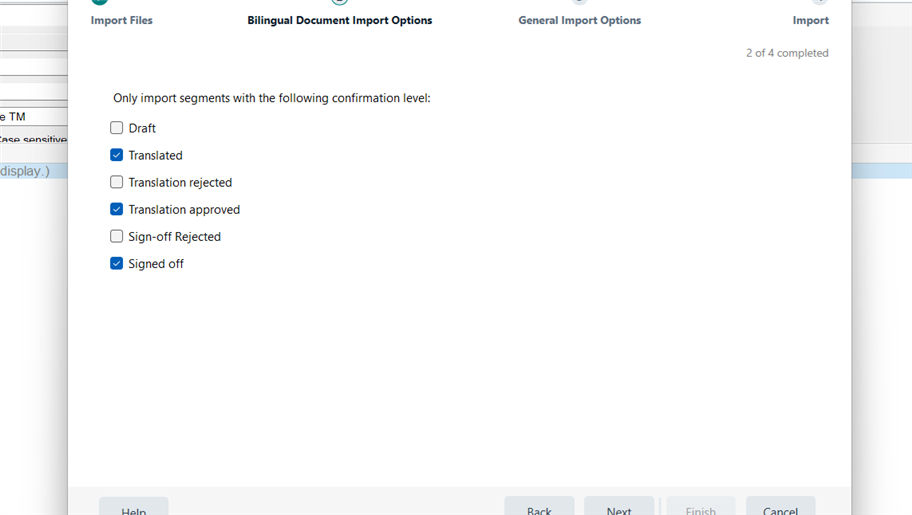
I frequently get bilingual files (xliff) from my client that need to be analyzed for discounts. Since I updated to Studio 2021 I get no fuzzy matches when analyzing files, only 100 % matches or context matches. Still I can see in the bilingual file that there are several fuzzy matches. What I do is I create an empty TM and import the clients xliff-file into the TM. Then I run the text file against that TM. Before I used to get the fuzzy matches in the analyze files report but not anymore. What could I be doing wrong?
Linn