Hi everybody,
I have created a project with a bilingual Excel.
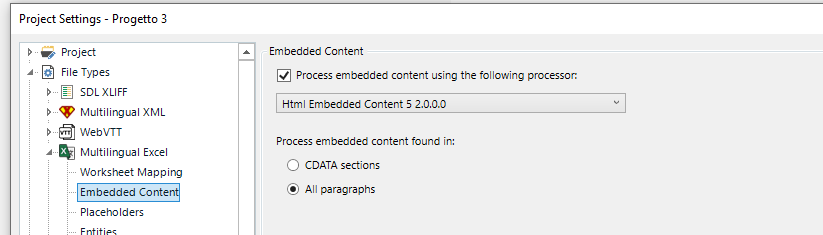
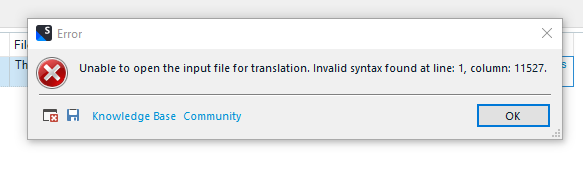
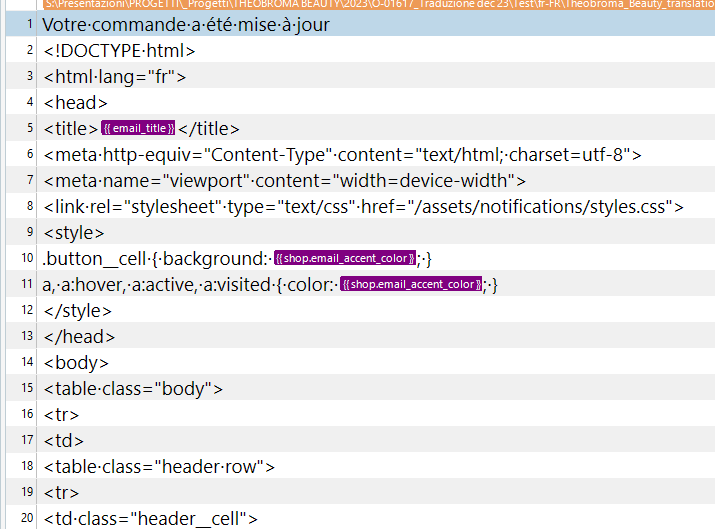
Despite setting all tags as "exclude" in the advanced view in the Filetype settings, I get this:
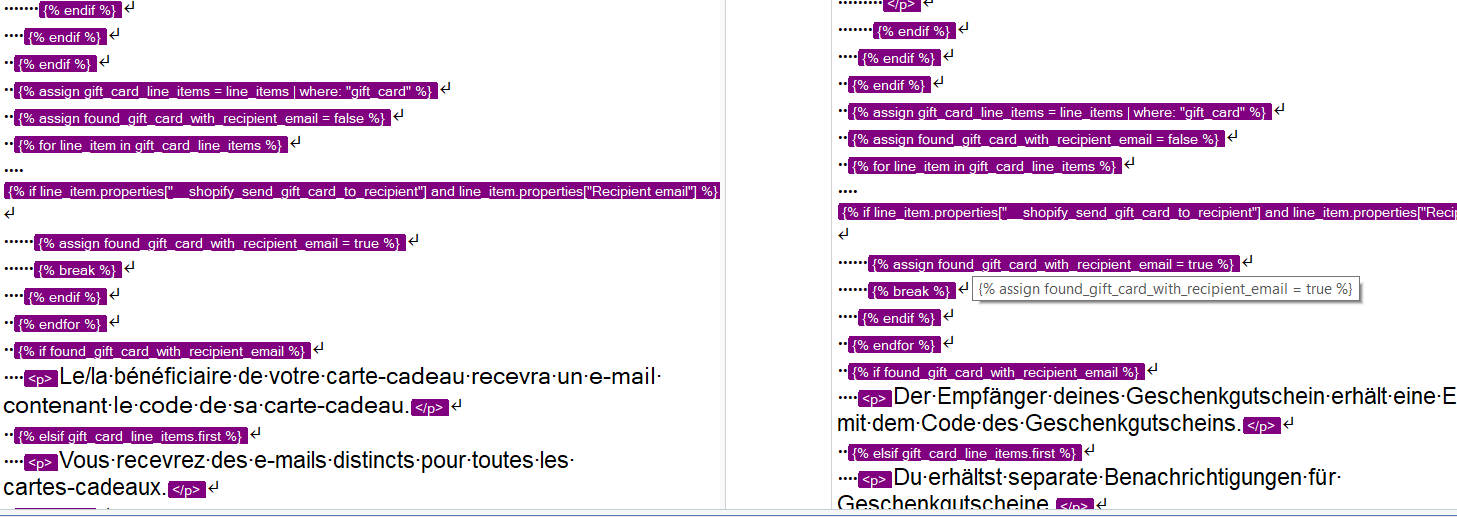
Is there a way to set the file so that I get a new segment at each soft line break?
Thanks
Generated Image Alt-Text
[edited by: RWS Community AI at 1:01 PM (GMT 0) on 14 Nov 2024]