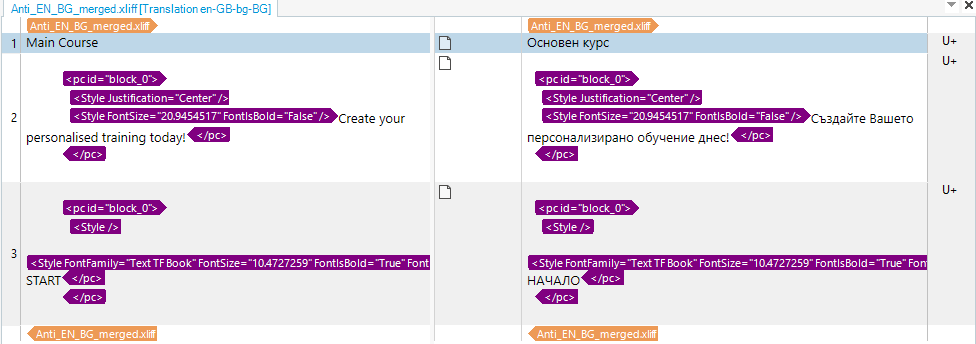
My client sent me 2 xliff files from Articulate. The one with Source and the one with Target. I need to create a TM from them for the new assignment.
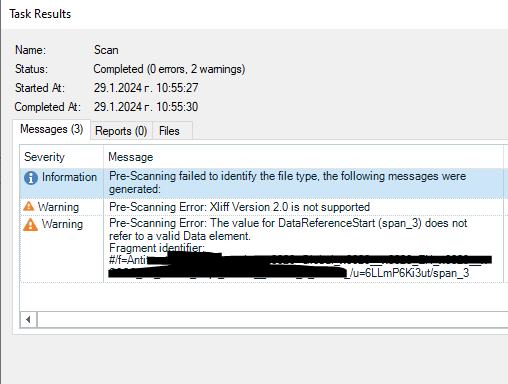
I tried to align both files using Align function in Trados Studio but I got the error that XLIFF 2.0 is not supported. Then I created SDLFLIXX in a project and tried to align those files, but again it says that XLIFF 2.0 is not supported.
My Trados verion: Trados Studio 2022 SR2 - 17.2.9.18688
Please, let me know how to proceed. The files are confidential, so I can send only a sample.
Thank you!
Sotir