Hi Team,
I would like to learn how Trados calculates the TM match rate.
I ran the word count analysis with Trados and another CAT tool, but there were discrepancies in the word counts. So would like to know how Trados calculates the match rate.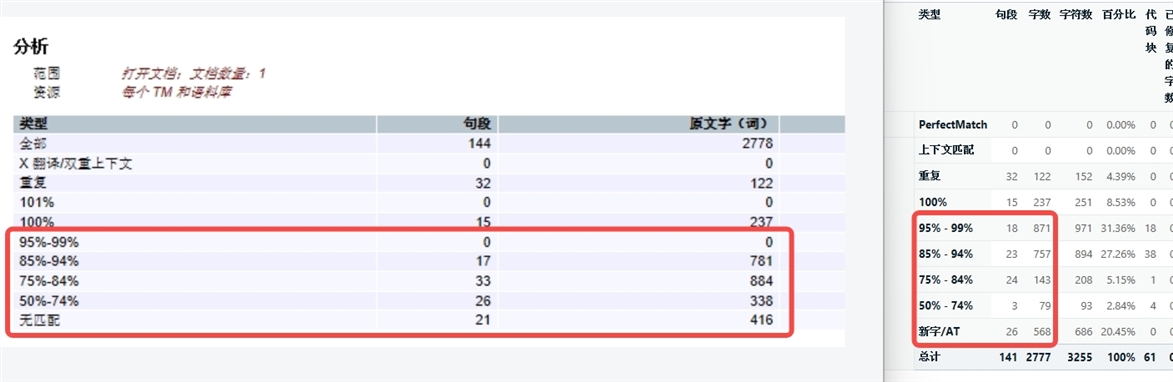
Generated Image Alt-Text
[edited by: RWS Community AI at 3:45 AM (GMT 1) on 19 Jun 2024]