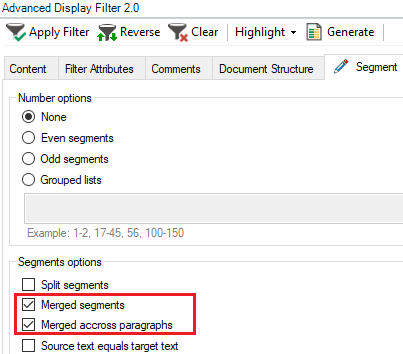
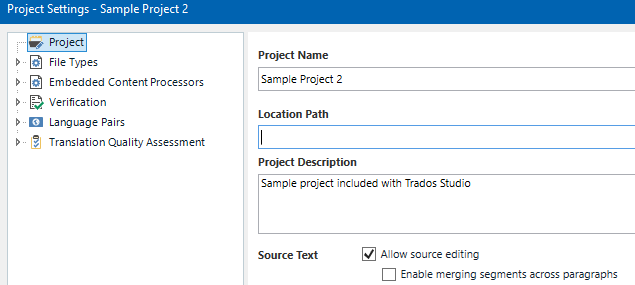
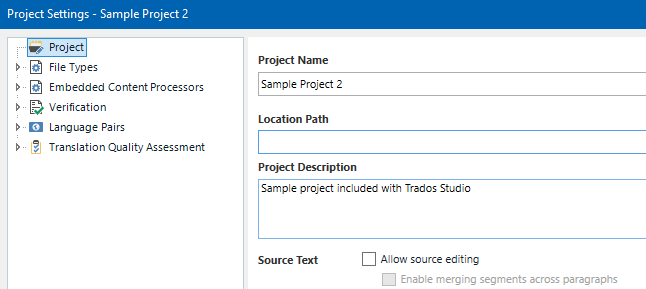
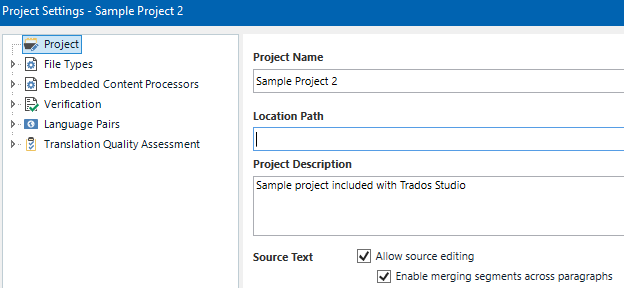
Hi, is it possible to prevent merging segments within same paragraph when creating a project in SDL Trados Studio and sending a package for translation? Further question if we cannot prevent merging segments, is there a way to check if segments have been merged? I know that you can open an sdlxliff file in Studio and visually check if the segment numbering is continous, but is there a way to automate the check?
Many thanks
Jouni