Hi everyone,
we've recently come across a strange issue related to alphanumeric string recognition in Trados Studio.
Project settings/conditions:
Project files are created by the customer in Trados Enterprise and received/processed by the PMs or linguists in Trados Studio 2024 (SR1).
All of the TMs used have alphanumeric recognition enabled in the TM settings.
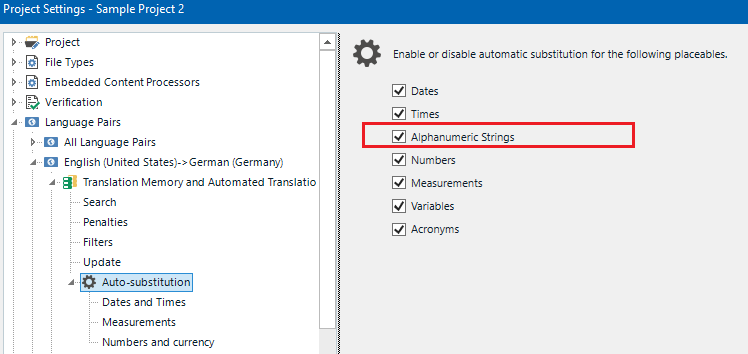
Auto-substitution is enabled for alphanumeric strings for each language pair.
There is no penalty applied to AT of alphanumeric strings.
Issue 1: Only a portion of the alphanumeric strings is marked as pre-translated.
In the translation editor, those segments are highlighted as CM, even though there is no exact match from the TM.
We assume that the pre-translations are indeed the result of AT, and we would expect Studio to mark them as AT, not CM.
AT, however, does not work the same way for all segments. The 99% segments basically have the same structure as the ones marked as CM,
but they don't have the same status.
So two questions here:
Why does Studio/Enterprise use a CM marker for something that is clearly an AT match with no entry in the TM?
And why are some segments treated as CM and others as 99% matches even though they should be treated equally?
Issue 2: For the 99% matches, Studio suggests various CM or 100% matches that clearly have nothing to do with the actual source text.
For example, the TM unit "PH2 > PH2" is suggested as a CM for "3601JK3200".
Translators obviously won't have a problem with that as they already have a pre-populated target segment with the correct string.
But this completely messes up the analysis results, as the Studio analysis will show more CM/100% (that usually are not paid for) than there actually are present in the project files.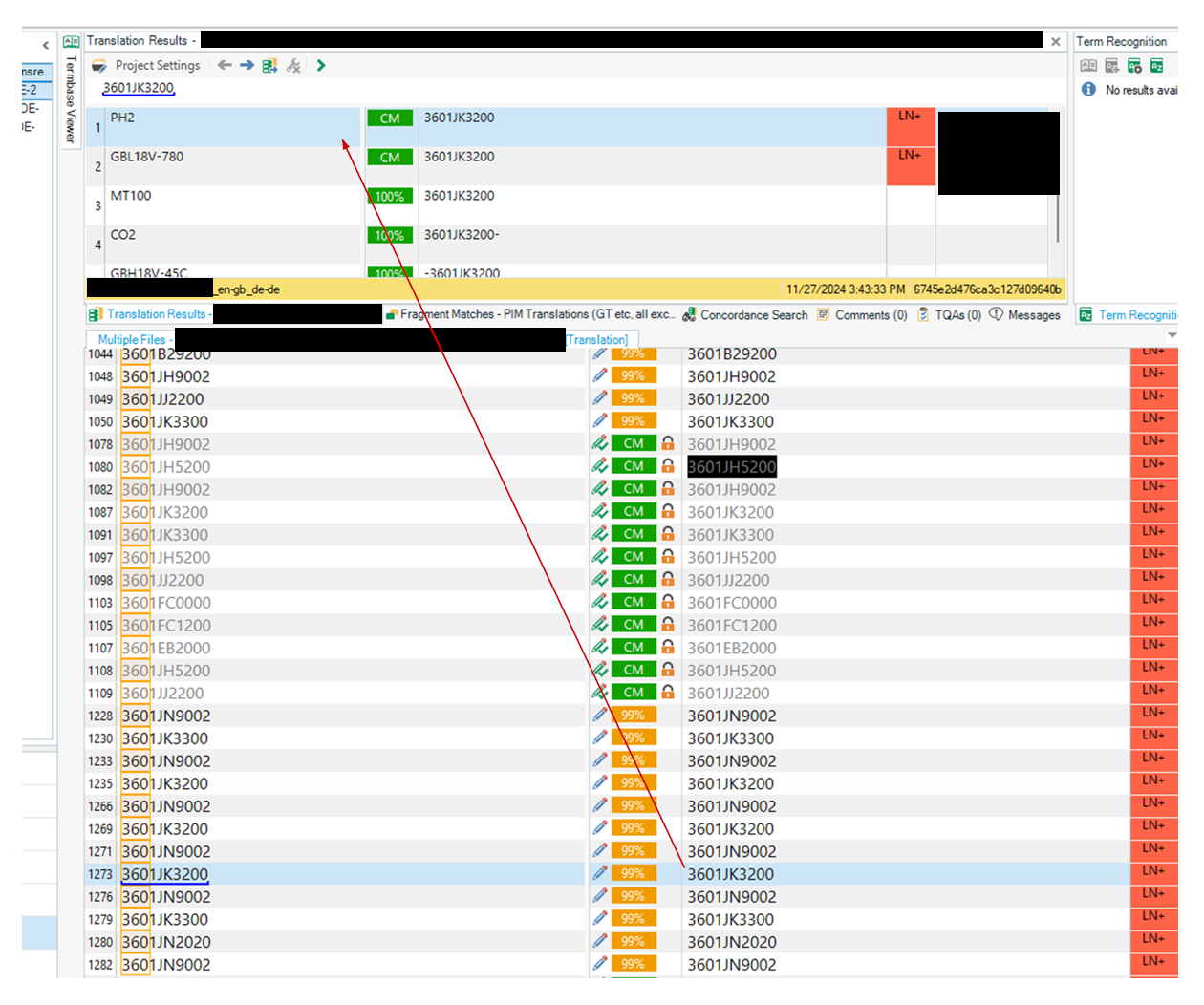
So what would be your take on this? Ask the customer to disable alphanumeric string recognition and AT altogether,
which would result in less AT hits? Or is there a defect with the recognition pattern that can be fixed in a future update?
Thanks in advance for your support!
Best regards,
Julian