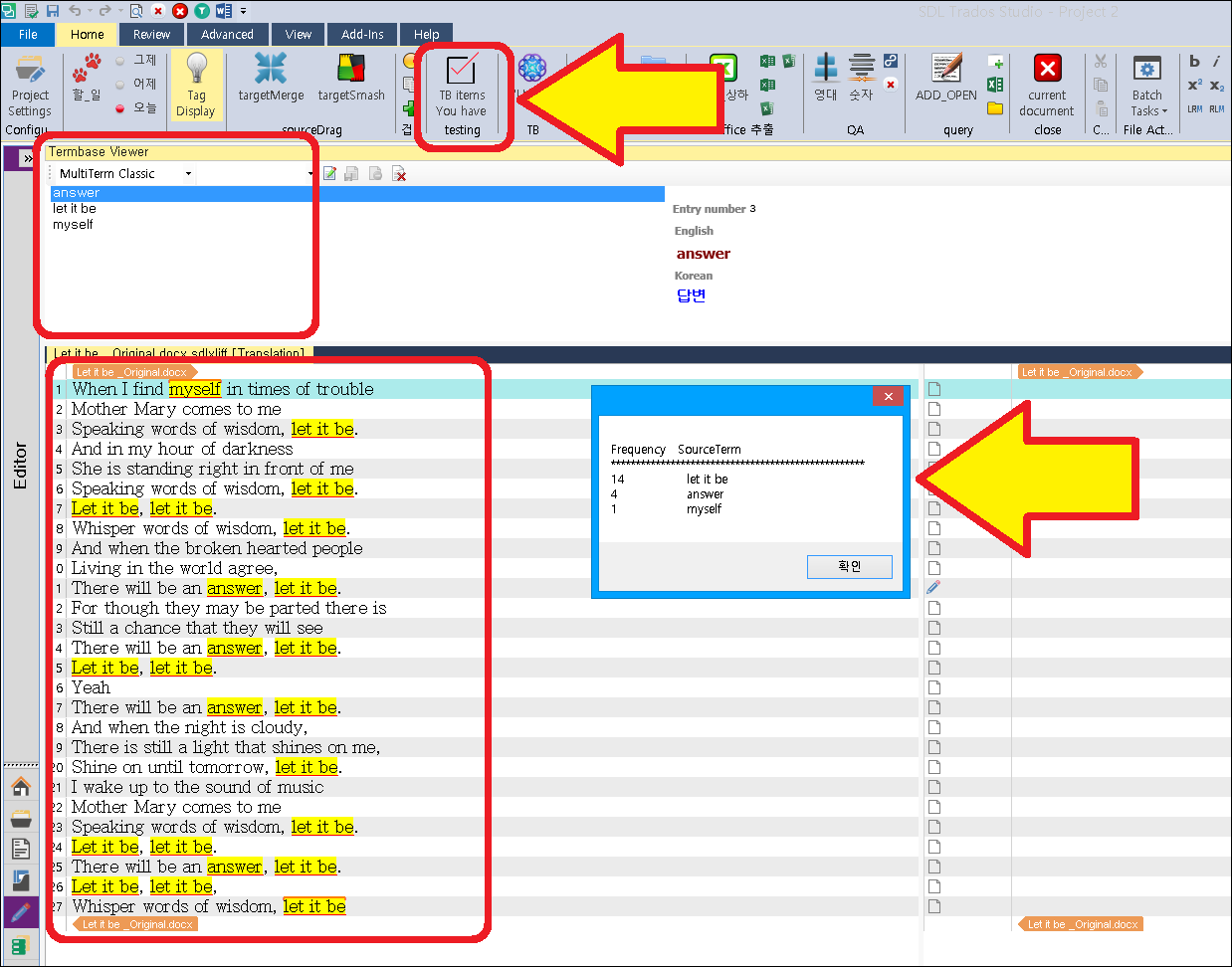
Good afternoon:
I would like to know if there is a proces or workflow to extract terms from a document using an existing Multiterm termbase, i.e. the workflow would detect in the original document only the terms already registered in the termbase and extract them into a new termbase to, for example, send it to a collaborator.
I have done my own research on this several times to no avail.
Thank very much.
Pablo Dittrich