Hi Paul,
I got a specifc urgent question. I got a survey xml from my client. I created a custome xml filetype for it to grab all translatable strings, but I also got a file with questions (IDs) to exlude. Is it possible to filter these via filetype?
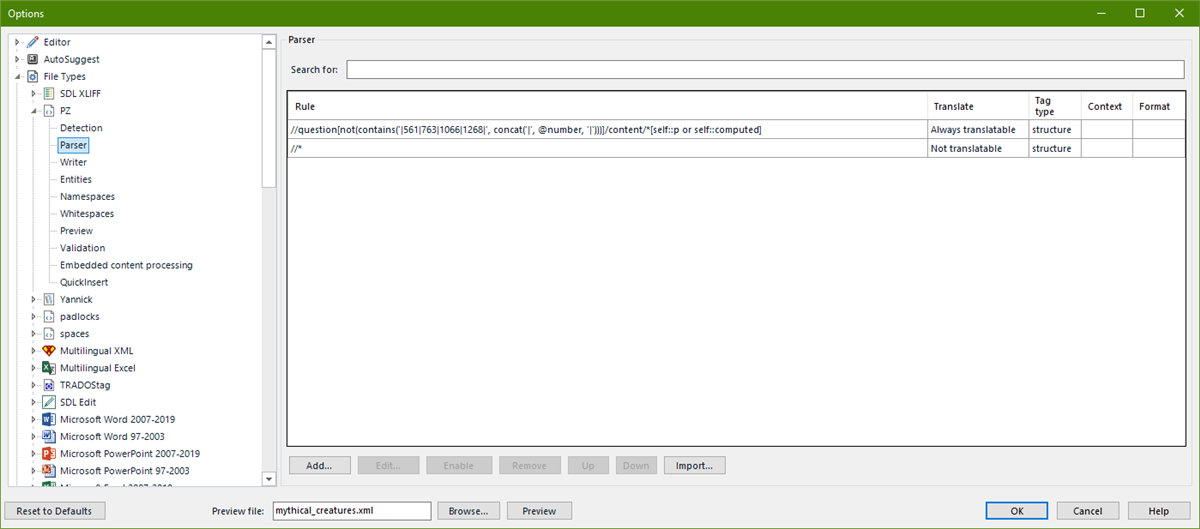
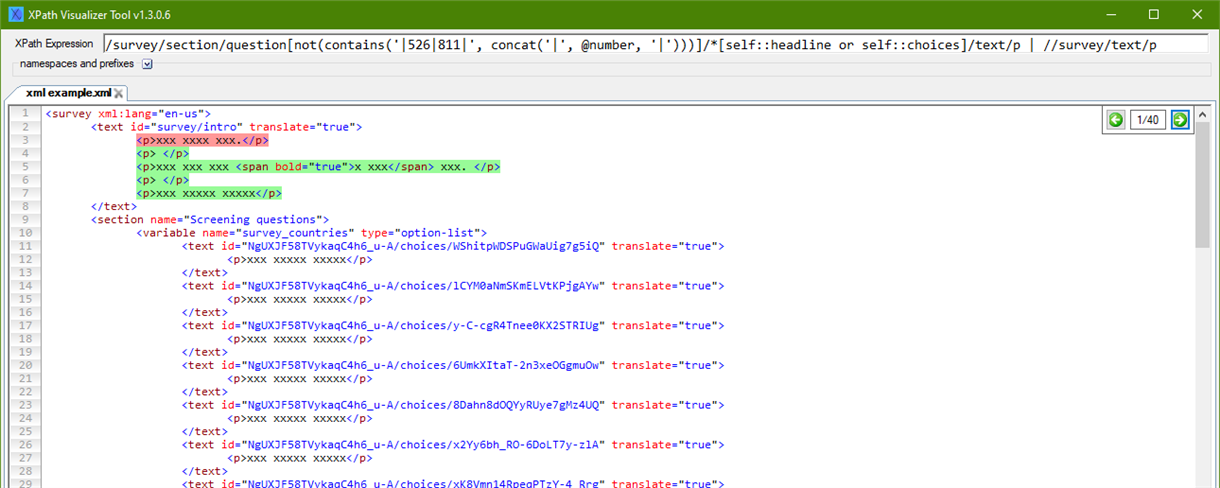
The inline elements to be translated are <p> and <computed> and they are nested within several parent elements of which the main one is <question number="x" type="xy">.
So my question is, it is possible to set up a filter to say only show <p> and <computed> for translation if <question …> attribute number is not any of listed ones (e.g. (regex) (258|259|260|1130|2255))?
Or maybe add a new element <exclude> around them, so they won't be listed for translation (I would then have to remove these before returning the translation)?
Best regards,
Pascal
better formulation of question while using correct terminology
[edited by: Pascal Zotto at 1:49 PM (GMT 1) on 15 May 2023]