

Those technical diagrams are killing me, everytime! Sometimes I got a PDF, sometimes I got a PNG...
I want to solve this from the begining... ! Any ideas?

Those technical diagrams are killing me, everytime! Sometimes I got a PDF, sometimes I got a PNG...
I want to solve this from the begining... ! Any ideas?
Rui ,
You have here how to deal with AutoCAD files:
http://noradiaz.blogspot.com/2015/09/translating-autocad-drawings.html
The free version will let you extract the first 50 words of the DXF file and hopefully is enough for you.
You have also https://www.translatortools.net/products/transtools/autocad-translation
You can try also the tool mentioned here: Translating Autodesk formats in SDL Trados Studio
As mentioned in the Ideas section, there are no plans to create a plugin for AutoCAD files:
Plugin for autocad
I guess the PDF and PNG files have been created via AutoCAD and are useful references to know the context while translating the DXF file.

Hi Jesús Prieto
Sorry to I reply in this old post again.
I have tried some similar methods, convert my some of pdf files to txt files. Then, I got some errors at the inline tags setting.
I tried to write some RE to exclude some patterns from translation, like this:
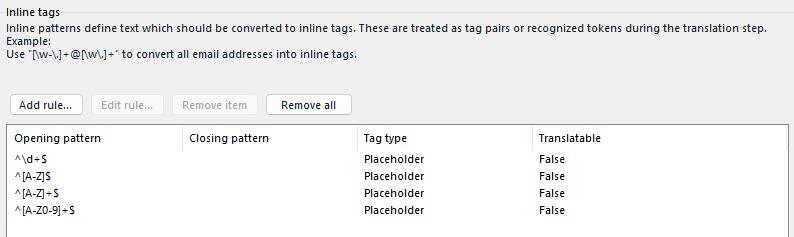
and when I try to finish create new project, I got lots of errors:

Here are one of the error's detail.:
<SDLErrorDetails time="2023/06/21 17:22:33">
<ErrorMessage>Problem during writing internal tags!
Check the definitions of your internal tags.</ErrorMessage>
<Exception>
<Type>Sdl.FileTypeSupport.Framework.FileTypeSupportException, Sdl.FileTypeSupport.Framework.Core, Version=1.0.0.0, Culture=neutral, PublicKeyToken=c28cdb26c445c888</Type>
<HelpLink />
<Source>Sdl.FileTypeSupport.Native.RegEx_1_1</Source>
<HResult>-2146233088</HResult>
<StackTrace><![CDATA[ at Sdl.FileTypeSupport.Native.RegEx.RegExParser.CompareSearchResultsAtSameIndex(RegExSearchResult& currentSearchResult, RegExSearchResult searchResultCandidate)
at Sdl.FileTypeSupport.Native.RegEx.RegExParser.RecordSearchResult(RegExSearchResult& currentSearchResult, RegExSearchResult searchResultCandidate)
at Sdl.FileTypeSupport.Native.RegEx.RegExParser.GetFirstMatchingRule(String processedString)
at Sdl.FileTypeSupport.Native.RegEx.RegExParser.GetFirstMatchingRuleBeforeMatchEnd(String processedString, Int32 lengthOfTextBeyondEndMatch)
at Sdl.FileTypeSupport.Native.RegEx.RegExParser.ProcessInternalTags(String& inputText, Match endMatch)
at Sdl.FileTypeSupport.Native.RegEx.RegExParser.ProcessText(String inputText)
at Sdl.FileTypeSupport.Native.RegEx.RegExParser.DuringParsing()
at Sdl.FileTypeSupport.Framework.NativeApi.AbstractNativeFileParser.ParseNext()
at Sdl.FileTypeSupport.Framework.Integration.FileExtractor.ParseNext()
at Sdl.FileTypeSupport.Framework.Integration.MultiFileConverter.ParseNext()
at Sdl.FileTypeSupport.Framework.Integration.MultiFileConverter.Parse()
at Sdl.ProjectApi.AutomaticTasks.Conversion.ConversionTask.ProcessFile(IExecutingTaskFile executingTaskFile)
at Sdl.ProjectApi.AutomaticTasks.AbstractFileLevelAutomaticTaskImplementation.Execute()]]></StackTrace>
</Exception>
<Environment>
<ProductName>Trados Studio</ProductName>
<ProductVersion>Studio17</ProductVersion>
<EntryAssemblyFileVersion>17.0.6.14902</EntryAssemblyFileVersion>
<OperatingSystem>Microsoft Windows 11 Home</OperatingSystem>
<ServicePack>NULL</ServicePack>
<OperatingSystemLanguage>1041</OperatingSystemLanguage>
<CodePage>932</CodePage>
<LoggedOnUser>DESKTOP-9M8MFGA\zhu</LoggedOnUser>
<DotNetFrameWork>4.0.30319.42000</DotNetFrameWork>
<ComputerName>DESKTOP-9M8MFGA</ComputerName>
<ConnectedToNetwork>True</ConnectedToNetwork>
<PhysicalMemory>8170024 MB</PhysicalMemory>
</Environment>
</SDLErrorDetails>
Any idea about what this is about? Did I used the wrong RE?

Hi Rui ,
I think you can safely delete the 3 first regexes, as they are only special cases of the 4th one.
Try and if it still doesn't work, please post the source document and export the file settings you are using, so I can have a look at it.

Hi Jesús Prieto
Thanks for reply.
I tried what you mentioned above, I deleted the 3 first regexes, no errors pop-up.
But the result also doesn't exclude those parts I don't want to translate.
Here is the editor view after applying only the 4th regexes:
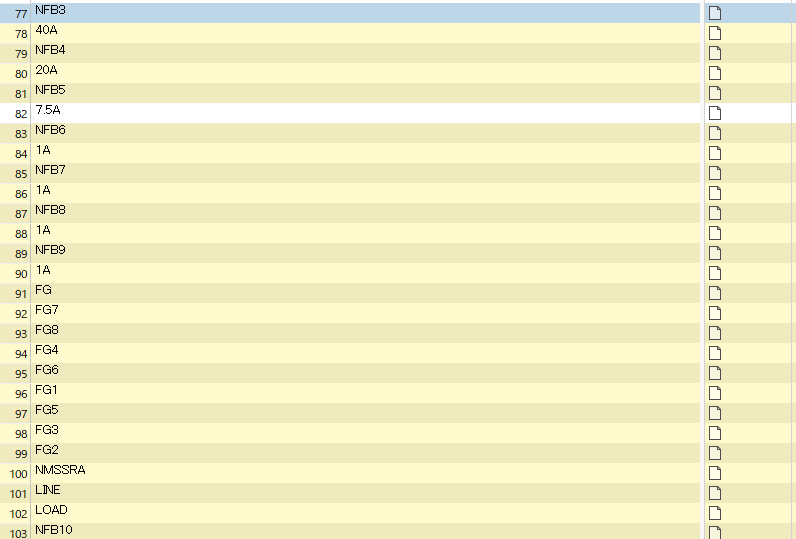
These Letters+Numbers combination are what I want to exclude from translation at first place, and they remain there after I apply the 4th regexes.
第3角法 副長 検図 設計 製図 課長 SHEET No. ESU-22045-40A4 電子式碍子汚損量測定装置 測定部接続図 △A1 ・新規作成(生産管理システム更新に伴い、品目番号変更) ・碍子昇降用モータ変更(2014/07/18) ・ジャバラ用モータ変更(2015/06/24) ・計測部ヒータをBI型に変更 (2015/06/24) ・碍子扉モータ変更 (2016/06/01) ・制御盤PCBユニット内電源変更 (2016/06/27) ・J1コンセント、T1トランス用FG追記 ・製造時の注記追加 2016/08/31 △A2 ・耐候性向上の為、SW1~3、SW10~17用ケーブル変更 2018/02/23 2018/02/23 △A3 ・蒸気発生器温度異常検出用タイマー設定変更、設定表追加 2019/02/25 2019/02/25 △A4 ・制御盤内保護回路変更 ・温度スイッチ、ヒータ定格追記 2020/01/20 2020/01/20 SW14 P L N SW15 P L N SW16 P L N SW17 P L N SW13 P L N SW12 P L N SW3 P L N SW2 P L N SW1 P L N P ジャバラ伸限 ジャバラ縮限 ジャバラ縮限過 N P 水位制御 断水 P 碍子上限 碍子上限過 N P 碍子下限 碍子下限過 N P フロートNo.1 フロートNo.2 P フロートNo.3 フロートNo.4 P No.1扉開 No.2扉閉 N P No.2扉開 No.1扉閉 N NMSSRA CN3-13 CN3-14 CN3-15 CN3-16 CN3-17 TB4-26 TB4-27 TB4-28 CN3-26 CN3-27 CN3-28 CN3-5 CN3-6 CN3-7 CN3-8 CN3-9 CN3-10 CN3-11 CN3-12 SW4 SW5 SW6 SW7 CN3-29 CN3-30 CN3-31 CN3-34 CN3-32 CN3-33 TB4-29 TB4-30 TB4-31 TB4-34 TB4-32 TB4-33 茶 黒 青 茶 黒 青 茶 黒 青 茶 黒 青 TB4-18 TB4-19 TB4-20 TB4-21 TB4-22 TB4-23 TB4-24 TB4-25 CN3-18 CN3-19 CN3-20 CN3-21 CN3-22 CN3-23 CN3-24 CN3-25 黒 白 赤 緑 黒 白 赤 緑 ①-黒 CN1-1 CN1-2 CN1-3 CN1-4 CN1-5 CN1-6 CN1-7 CN1-8 ①-黄 ②-白 ②-黄 ③-赤 ③-黄 ④-黄 ④-青 SW8 SW9 CN1-1 CN1-3 CN2-1 CN2-3 黒 黄 黒 黄 TB4-13 TB4-14 TB4-15 TB4-16 TB4-17 緑 黒 白 赤 黄 黒 青 茶 黒 青 茶 黒 青 CN_JSW-A1 CN_JSW-B1 CN_JSW-B2 CN_JSW-B3 CN_JSW-A3 TB4-5 TB4-6 TB4-7 TB4-8 TB4-9 TB4-10 TB4-11 TB4-12 茶 黒 青 茶 黒 青 茶 黒 青 茶 黒 青 黒 白 赤 緑 黒 白 赤 緑 CN_GUSW-A1 CN_GDSW-A1 CN_GDSW-B1 CN_GDSW-B2 CN_GDSW-A3 CN_GUSW-B1 CN_GUSW-B2 CN_GUSW-A3 SW11 P L N SW10 P L N 茶 2 4
I'm not so sure how to upload the document here. Can you see the txt file I uploaded?
Here is an example file I used. I tried to exclude all the numbers and capital letters from translation, but it didn't work like I expected.

Rui ,
ok, so there is nothing in the TXT that you can take advantage of.
You can find a regex to match those strings you don't want to be extracted and add as many regex rules as needed. The following are examples that you can use:
The regex to match alphanumeric strings such as NGB3 is:
^[A-Z]+\d+$
Add it along the rule you already have as a placeholder and Translatable = False.
Another example is 1A and 20A. If you need them to be extracted, the regex to be added is:
^\d+A$
Another can be CN_GUSW-A1, which can be:
^CN_GUSW-[A-Z]+\d+$
Lines consisting of a single letter:
^[A-Z]$
Lines consisting of only digits:
^\d+$
One last example. If you need to get rid of Japanese-only lines, you can also this rule:
^([一-龯])$
I hope these regexes help you and give you some ideas. As I said, add as many rules as you need.
Perhaps an interesting approach based on what I think I'm seeing here is to create a default regex delimited text filetype, but then use a rule like this as an inline tag:
^[^\u3400-\u4DBF\u4E00-\u9FFF\uF900-\uFAFF]+$
That will filter out all the strings that don't contain Chinese characters so you're left with this:

Paul Filkin | RWS
Design your own training!
You've done the courses and still need to go a little further, or still not clear?
Tell us what you need in our Community Solutions Hub
Thank! That's very helpful!
The problem is that since I have more than 100 files like this, there so many patterns of [letters+numbers], it doesn't always use "CN_GUSWxxx". The combination could be any letter, and the "_" (underline mark) or "-"(hyphen) could be anywhere between these letters and numbers.
I really don't want to write all those in regex... :(

