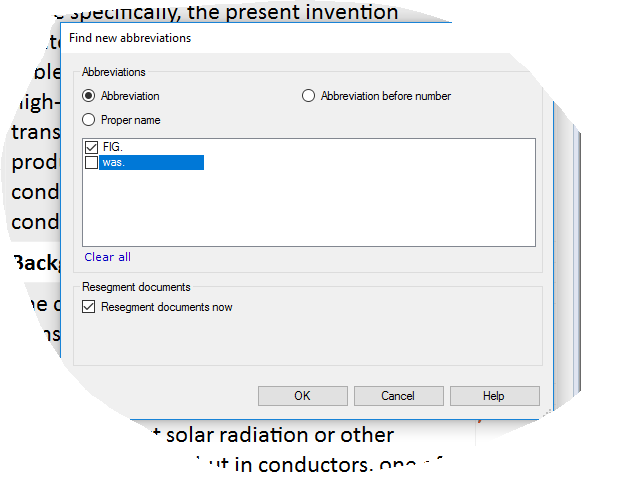
OK, in memoQ, when you run into an incorrectly segmented segment caused by e.g. an abbreviation, you can quickly add it to your segmentation rules for the current src language, and even re-segment your entire project (if you want). E.g., I just ran into this problem, as Studio segmented on "FIG.", I don;t want it to do this. How can I quickly tell Studio not to break on "FIG."?
Michael