Hello,
I don't know why some segments in all languages do not enter in the TM during the updating process. I tried to create a new project just with the sentences I need but no success.
The example below:
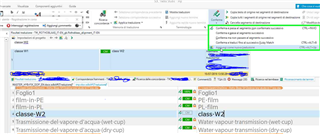
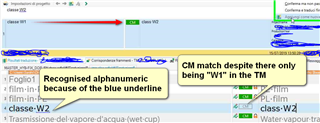
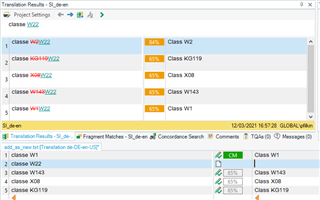
I my TM (in this case IT>FR) i have the segment "classe W1", in my project I have "classe W2", with pretranslating task the "classe W2" is automatically translated as CM, and that's ok, even if i cannot understand why in the TM view i see"classe W1" and the relative (wrong) translation "classe W2" (see pic below)
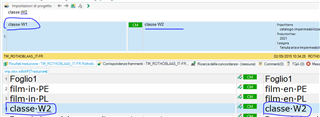
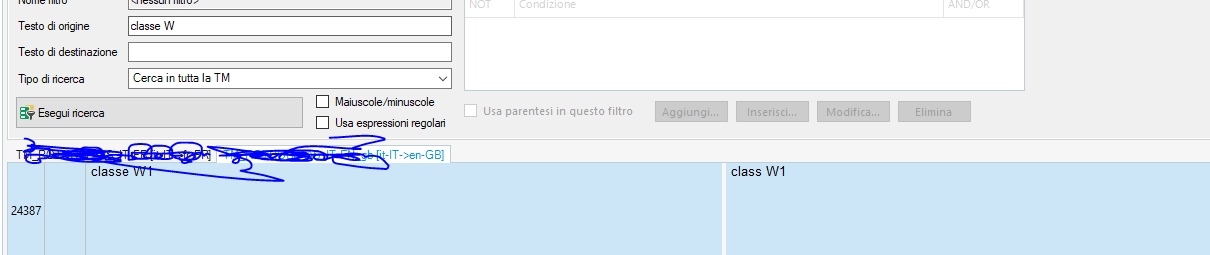
Then I updated the TM and if I open the TM and search "classe W" i just find the "classe W1" solution (in this case correctly).
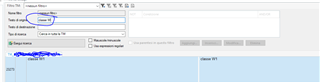
Why is "classe W2" not in TM? I need to have this as the TM is connected to our CMS where the sentence is.
Thanks in adavance
Sarah
Generated Image Alt-Text
[edited by: Trados AI at 1:32 AM (GMT 0) on 29 Feb 2024]