


Hi,
I have a source text in which there are segments in English mixed with previously translated segments (Spanish).
Can I hide the already translated text in the editor and see only English segments in the source text column?
Thanks,
Marta

Hi,
I have a source text in which there are segments in English mixed with previously translated segments (Spanish).
Can I hide the already translated text in the editor and see only English segments in the source text column?
Thanks,
Marta
Hi Jesús,
The source text has both languages together, some segments are in Spanish and others in English (example attached).
It is a software translation and the colleague preparing the files has them mixed, for some reason.
I have tried the first option you included, but when applying the filter, nothing happens.
I thought the tool would have a simple way of recognising different languages in the ST, and it wouldn't be difficult to hide one.
The doc is longish. I don't think I want to manually lock all Spanish segments.
Thanks,
Marta
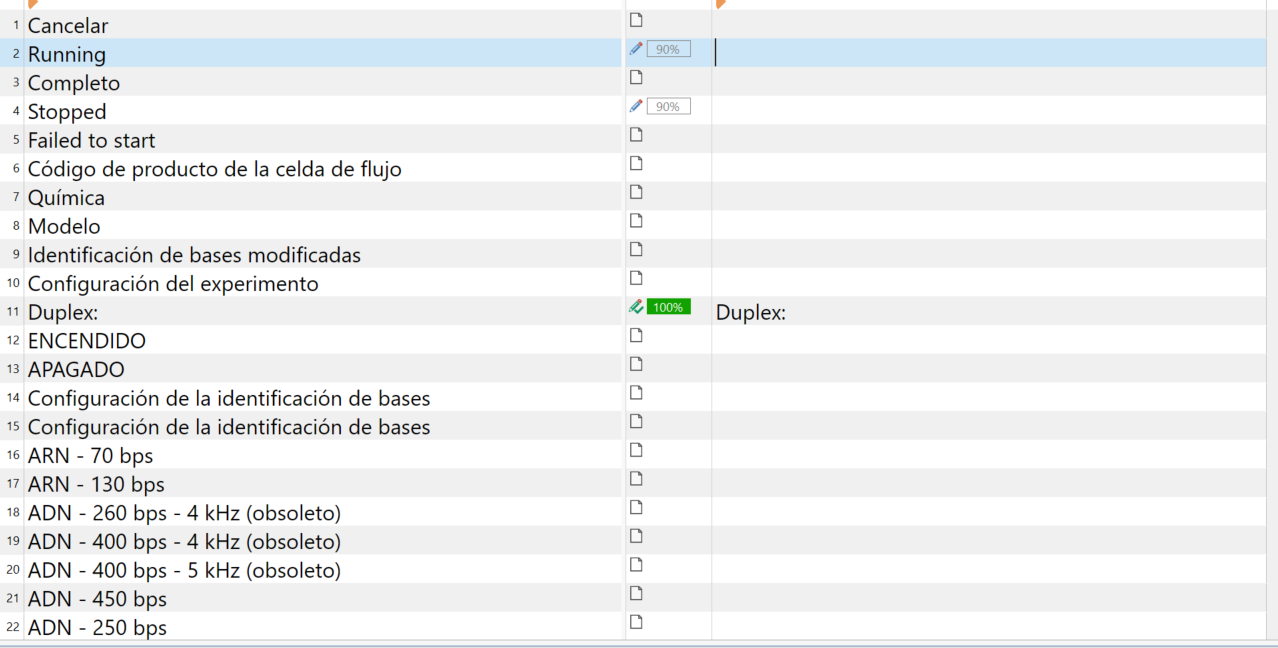

Hi Jesús,
The source text has both languages together, some segments are in Spanish and others in English (example attached).
It is a software translation and the colleague preparing the files has them mixed, for some reason.
I have tried the first option you included, but when applying the filter, nothing happens.
I thought the tool would have a simple way of recognising different languages in the ST, and it wouldn't be difficult to hide one.
The doc is longish. I don't think I want to manually lock all Spanish segments.
Thanks,
Marta

There is no way to do that out of the box. You can try to autodetect languages in MS Word and hide one of the languages, but with such short words and phrases it can be difficult for MS Word to recognize the language correctly. How do you say 'hospital' in Spanish? And what about 'chocolate'? Let me guess: 'animal', 'digital' and 'original' are the same story. I mean there are many identical or similar words in English and Spanish and you may need longer sentences to identify the language. Modelo can be a misspelled English word or a word in Spanish or Portuguese. That is why you (or your colleague) have to prepare the document properly before you import it into Trados rather than after.


A picture is worth more than a thousand words!
I agree with Stepan Konev that there is no automatic way to do it.
Which is the source file, I mean, a TXT an XML? And could you please post a snippet of the first lines to show the lines of your screen shot? May be Spanish texts ara cleearly differenciated from the English ones, and then we can deal with them…
As a last resort, you can filter out segments with Spanish specific characters, such as áéíóúüñ, and maybe you can lock 40 % of the segments, but I’d recommend exploring the possibility mentioned above, and for doing so, we need a sample of the source file.

Hi Stepan,
You are very right. I hadn't thought about the similarities of the romance languages and also with English.
I think I will just work as it is and perhaps talk to my colleague for the next time.
Thank you,
Marta

Hi Jesús,
The source text is a JSON file that I can't, or I don't know how to preview. When I open it, it opens on Trados right away. Second Image shows the beginning of the document, not sure if this is what you meant.
It's not a massive problem to leave it as it is. I thought, hiding it would help to make sure I won't miss anything in the translation, but I will be careful and review a few times before I send it back, and I will talk to my colleague before he works on the next software update.
Many thanks for your assistance, though.
Regards,
Marta
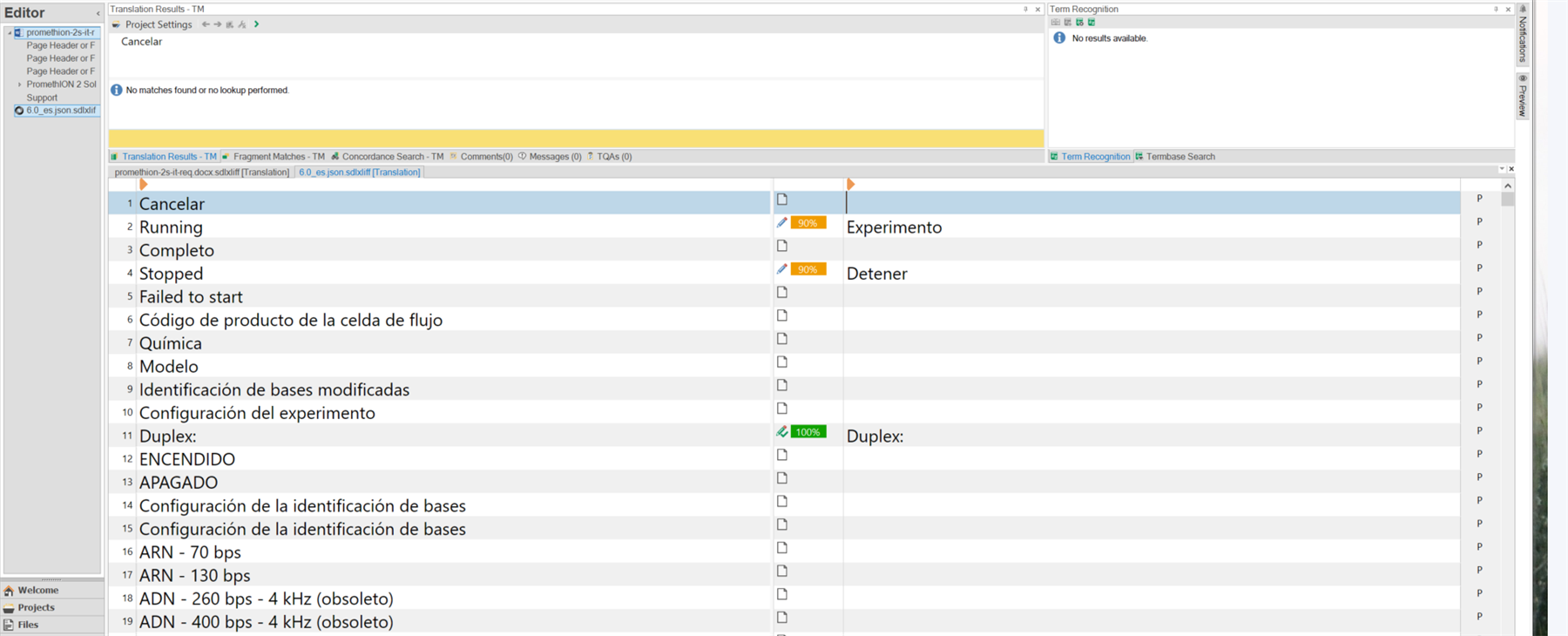
The source text is a JSON file that I can't, or I don't know how to preview.
You can open JSON files with any editor, such as Notepad or Notepad++, since it’s a plain text file.
Being a JSON file is good news, since you will be able to tweak the way Trados Studio parses the file.
I bet there is something in the JSON differenciating English from Spanish strings.

I opened the file on Notepad.
The only thing I can see is that the strings that haven't been translated are repeated.
Any idea?
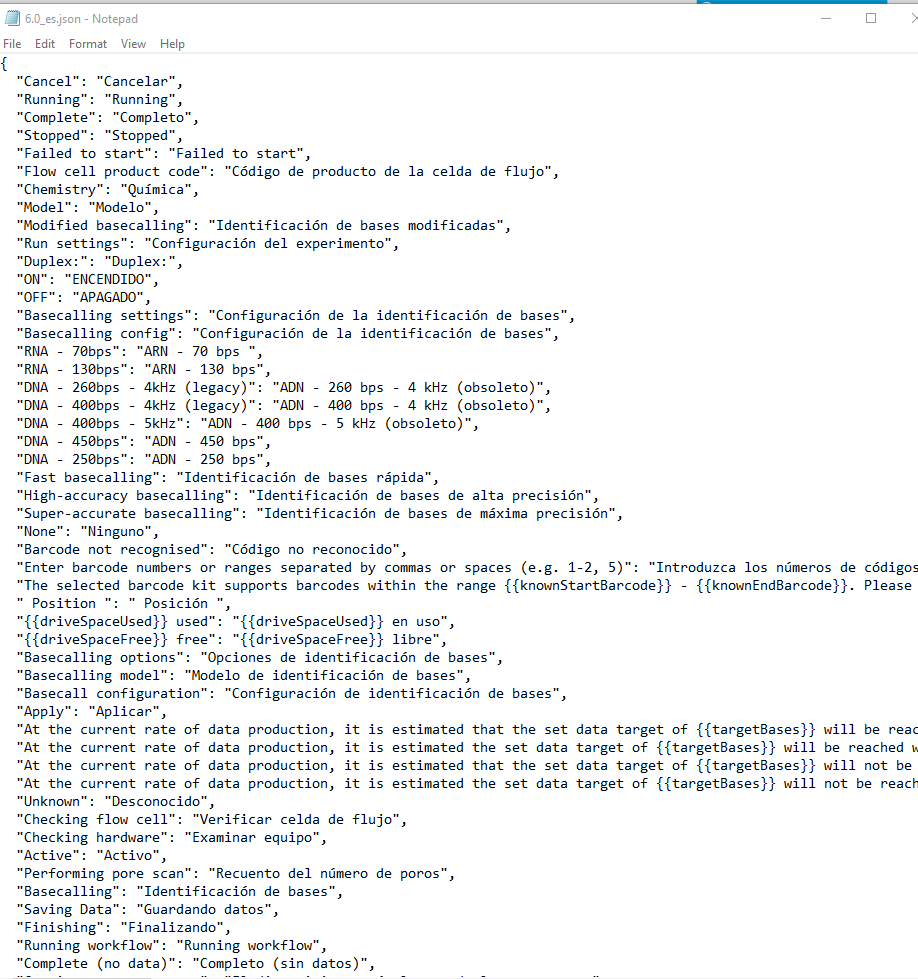
The layout is "[English here]": "[Spanish here, even if untranslated]".
So far Trados Studio is extracting both English and Spanish.
Please search for "JSON" in this forum and try to find the way in other already answered posts. I’m not good a JSON settings, so I can’t quickly help. If you can’t find the way, get back to this post and ask how to do it and other peers may help you.
And don’t forget to reject my answer above, so other peers can see this post as still unanswered…
I see.
I'll do that.
Thank you
I hope your research goes well.
A couple of things:
If nothing works, I’d prepare it in the old way, when there were not so many useful filetypes: In Excel!
And this is the way:
Copy the whole content of the JSON file and paste it to the first column of an empty Excel spread sheet. Use the columns on the right to extract both the English and Spanish strings, and compare them. If they are the exactly the same string, set that cell with the content of the English text; if they are different, it means that they have been already translated, so leave that cell empty. You can do this via Excel formulas.
At this point you have a column with only English strings to be translated, correct? Copy and paste this column to an empty TXT, save it and open it in Studio. You’ll need to set some placeholders as tags in Studio, such as {{SOMETHING_GOES_HERE}}.
After translation of the TXT, copy and paste the translated text into another column in the previous Excel spread sheet. Now use more formulas to merge the original line with your translation. The logic behind is that if English and Spanish original strings are different, then the original line goes to the cell; if they are the same, then your translation shoud be used instead of the original Spanish string. If you have followed me till here, now you just need to copy that final column and replace the content of the original JSON file, and that's it!
You can have this working in one hour. Not fun, but maybe better that locking segments in Trados Studio.
You can try this regex replacement in Notepad++ (make a copy before you proceed with replacing):
Find what: ("[<>\.\,\;\:\?\!\(\)\{\}\[\]0-9\w+_\s-]+"):\s((?>(?!\1))"([^"]+)")
Replace with: \1: "\3 @@@"
Then import the new file into Trados.
The translated segments in Spanish would be marked with " @@@" . Then you can filter for @@@ in source, copy source to target and lock all with Ctrl+L.
Then translate the unlocked segments and save target as *.json. Open the target file with Notepad++ again and delete all instances of " @@@" by replacing it with nothing (blank Replace with field).
If there are some characters in your strings that are not present in the find what regex, the replacement won't work for that string and you may need to modify the regex by adding the missing characters.