I am looking for a way to achieve at least document-level context for MT and AI. The current solution is to run an AI platform in parallel and copy/paste from Trados Studio to the AI platform. There, and agent is equipped with the entire document (and reference material, if there is). I then manually paste the response back into Studio. So far, so good, but this is painfully manual and very slow.
I'd like to be able to tell Studio's AI assistant:
“Include the preceding X segments (or paragraphs) in your request. With (or without) translation.”
“Include the succeeding X segments (or paragraphs) in your request. (With or without translation, for the sake of completion, although this will usually be without unless I am in the role of the reviewer.)
I created an idea for this, please support: Context-awareness for AI Assistent
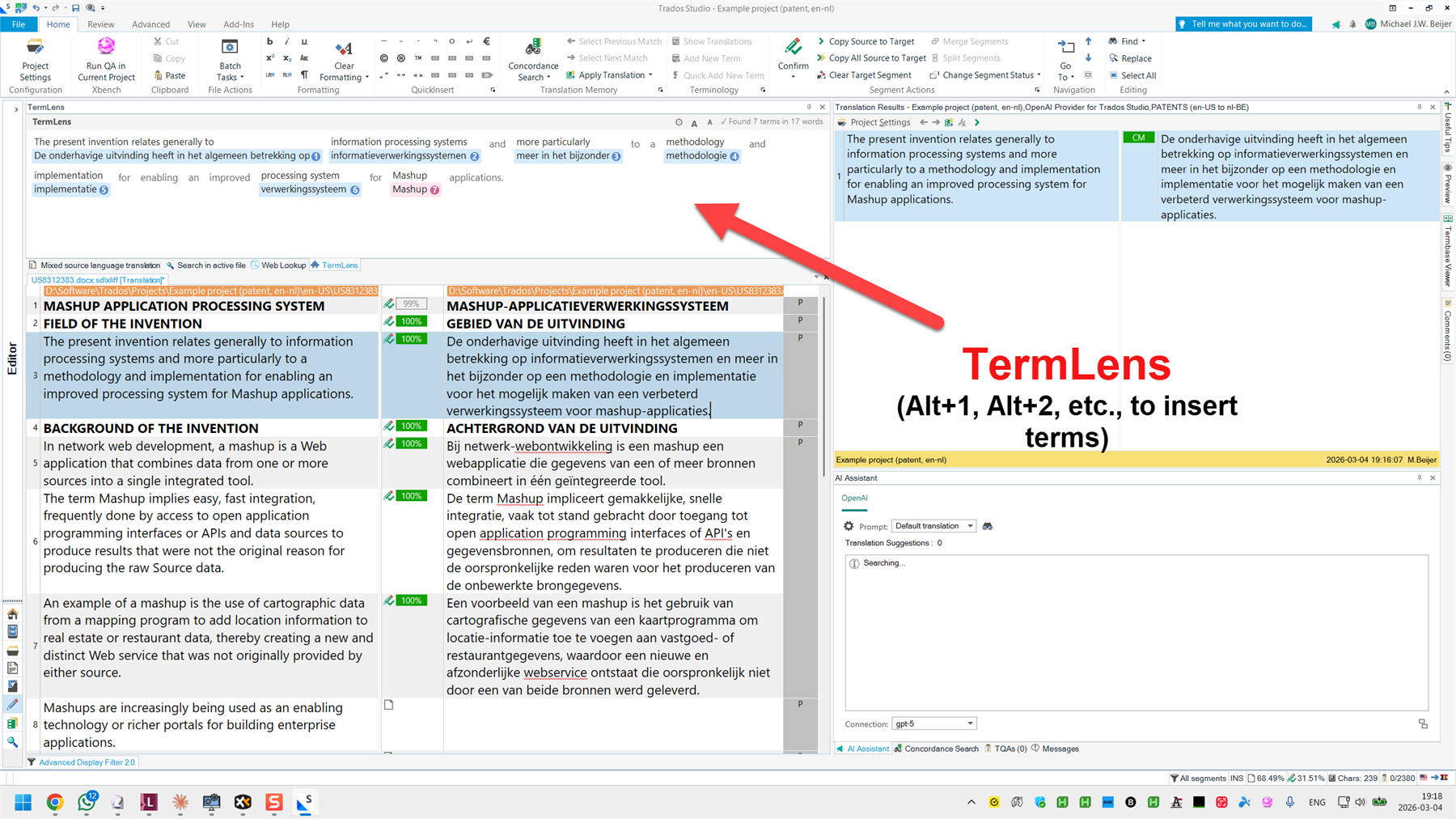
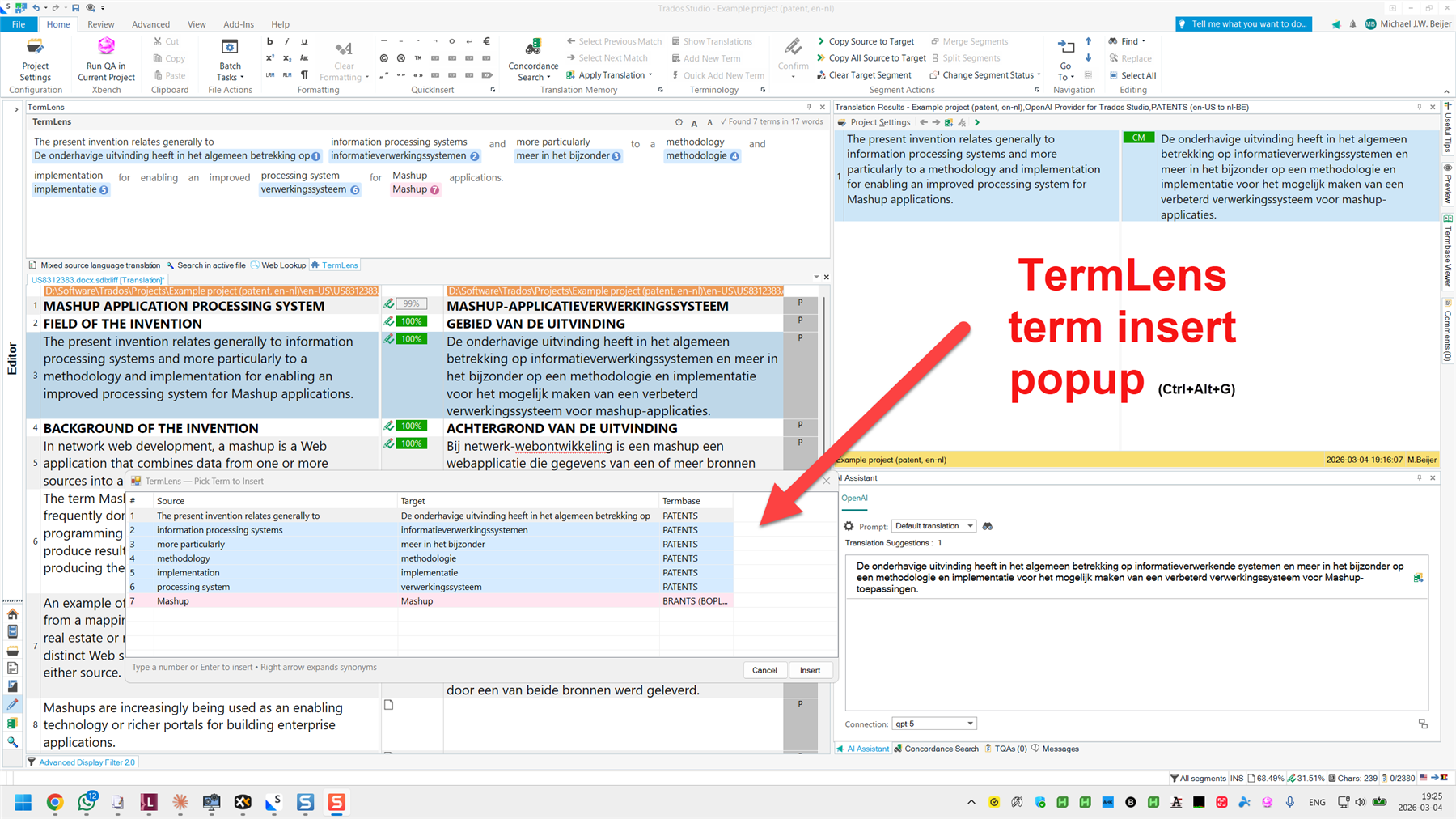
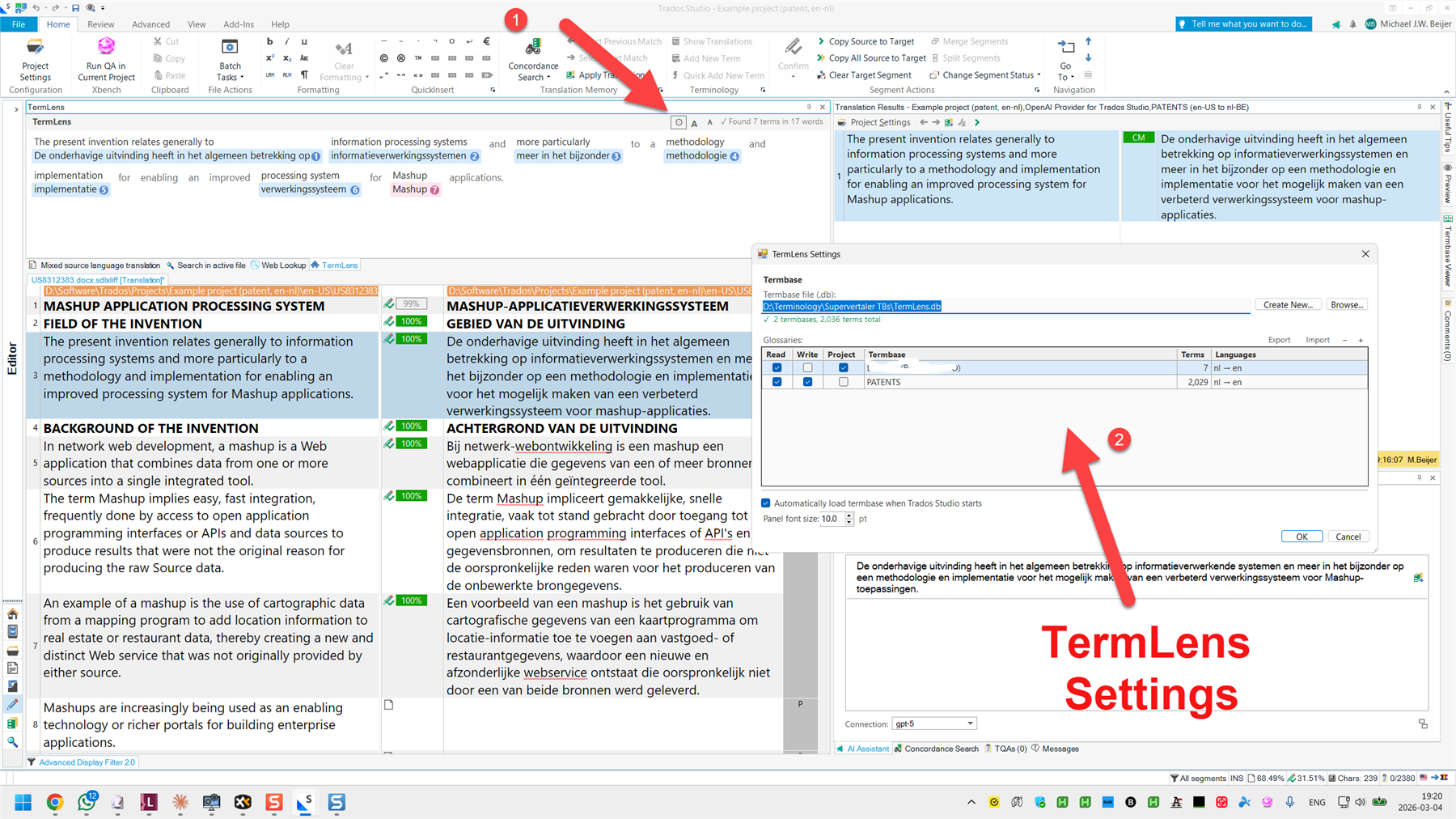
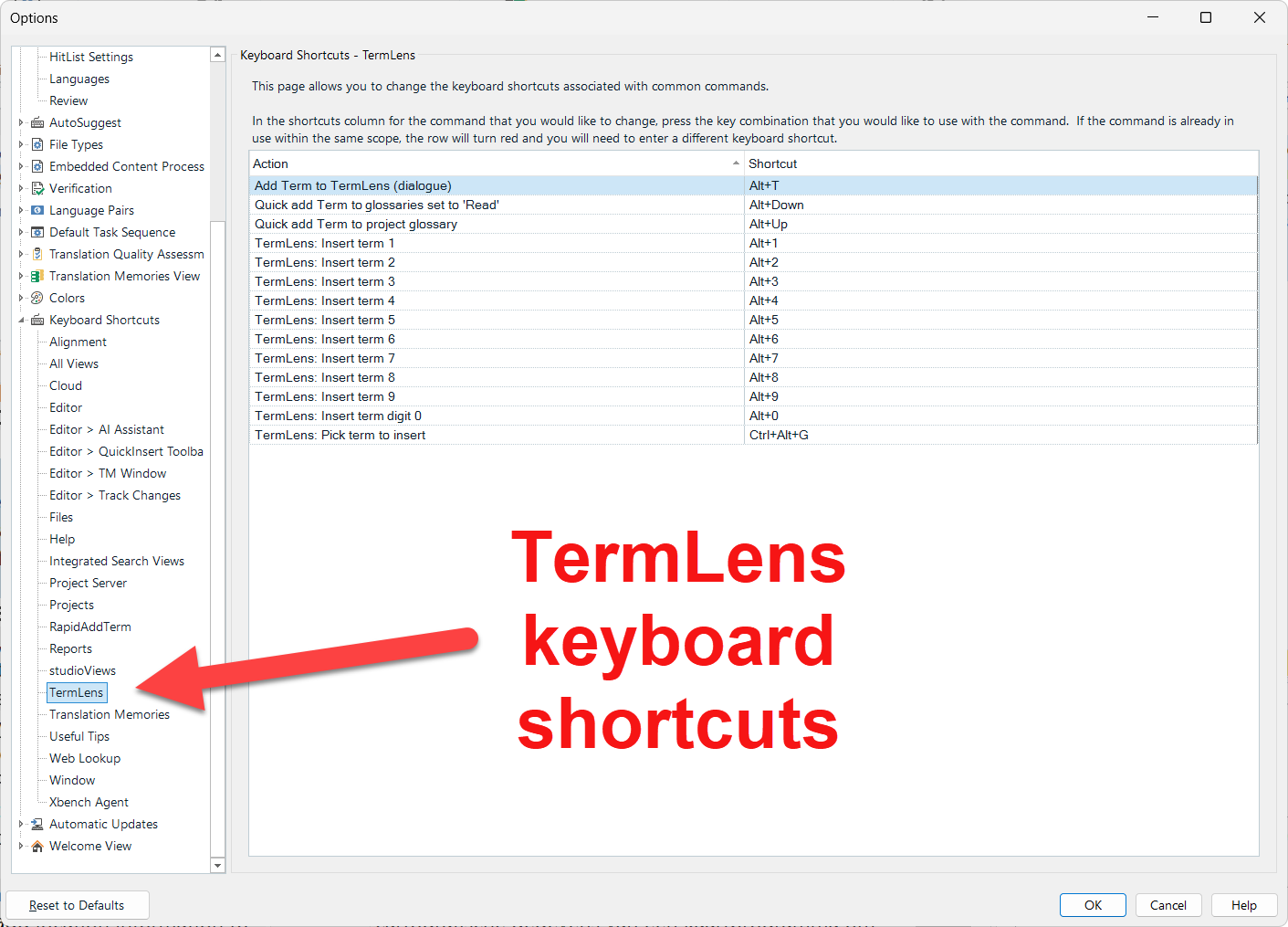
For terminology, very, very important: Include such-and-such a field in your request. This is how I can tell AI not to use TB entries with the status “deprecated” or “superseded”. There is an idea for this already, please support: OpenAI Provider for Trados Studio: option to include term information in system prompt
A lot happened recently with the AI Assistant (user can modify the system prompt)! Thank you for that!
Removed AI Suggestion
[edited by: Daniel Hug at 10:17 AM (GMT 0) on 13 Dec 2025]